
Machine Learning model is software that can learn and respond through experiences. Machine Learning has a wide range of applications in various fields of technology and science. Many top companies give preference to machine learning as one of the most important domains. For example, Amazon, Netflix, Facebook, Youtube all these companies use Machine Learning algorithms to improve customer experience. Since Machine Learning is a much established and more blooming field, it is a great career option one may choose. So, in this article, we will learn how to Deploy Machine Learning model using Streamlit.
The ultimate goal of the Machine Learning model is to make use of provided data and make better predictions. There are some steps to build a machine learning model. https://copyassignment.com/8-steps-to-build-a-machine-learning-model/. One of the most important and final steps in building a Machine Learning project is Model deployment. There are many frameworks available for deploying the Machine learning model on the web. Some of the most used Python frameworks are Django and Flask. But these frameworks require a little knowledge of languages such as HTML, CSS, and JavaScript. So, a new framework known as Streamlit was introduced to deploy the Machine Learning model without the need of having the knowledge of Front End Languages. It is quite easy to deploy using Streamlit.
What is Streamlit?
Streamlit is an open-source and user-friendly framework designed to create and deploy Machine Learning models. It is used to deploy the Machine Learning models as web apps in a minimal amount of time. Streamlit is much simpler and requires a minimal amount of code compared to other frameworks. Since Streamlit is a new framework lot of new features are being added in the subsequent releases.
Features of Streamlit
- The web app created using Streamlit automatically gets updated when the changes are made in source file.
- Streamlit framework is compatible with most of the Python libraries such as Numpy, Pandas, PyTorch, Matplotlib, Keras, etc.,
- The code to deploy our model is the same way as we write Python code.
- No need to worry about the front end development.
- It is extremely easy and simple to learn.
- The development and deployment time is super fast.
- Since widgets are treated as variables it is quite easy to implement.

How to install Streamlit?
Before installing Streamlit, make sure you have installed Python in your system.
To install Streamlit run the following command in the command prompt or terminal.
pip install streamlit
Open a python file and import the Streamlit framework use the following command
import streamlit as st
To deploy and run the web app on the local web run the following command.
streamlit run filename.py
The web app runs on port 8501 by default. You can check the output in the browser. After making any changes to the source code, rerun the app using the option available over the right top corner. Or use the option always rerun to automatically update the changes to the web app.
Important functions in Streamlit
Streamlit has many features and functions to deploy the content on the web. Some of the important and most used functions are discussed below.
Title
The title widget is used to specify the title for the page.
# Importing Streamlit
import streamlit as st
# Title widget
st.title(“Deployed with Streamlit”)
Output:

Write
Write function accepts data formats, such as text, numbers, data frames, styled data frames, and assorted objects.
import streamlit as st
import pandas as pd
# Write widget
st.write (“This is a Web App”)
st.write (1234)
st.write (pd.DataFrame({
‘first col’: [1, 2, 3, 4],
‘second col’: [1, 4, 6, 8],
}))
Output:

Text elements
Some of the text elements include the header, Subheader, caption, text, and latex.
import streamlit as st
# Text widgets
st.header (“This is a header”)
st.subheader (“This is a subheader”)
st.caption (“This is a caption”)
st.text (“This is a text”)
Output:

Code widget is used to specify the code on the page.
import streamlit as st
code = ”’def function():
print (“This is a web app!”)”’
# Code widget
st.code (code, language=’python’)
Output:

Text color
import streamlit as st
st.success (“Success”)
st.info (“Info”)
st.warning (“Warning”)
st.error (“Error”)
Output:

Check box and Radio button
import streamlit as st
st.text (‘Check Box’)
#checkbox
st.checkbox (‘Option 1’)
st.checkbox (‘Option 2’)
#radio button
st.radio (“Radio button”,(‘Option1′,’Option2’))
Output:
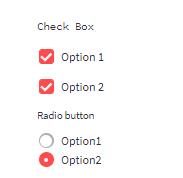
Selection Box
Any one option can be selected from the selection box. In Selection box first argument takes the title of the selection box second argument takes the options.
import streamlit as st
#Selection box
st.selectbox (“Selection box “, [‘Option 1’, ‘Option 2’, ‘Option 3’])
Output:

Text Input and Button
import streamlit as st
st.text_input (“Text Input”)
st.button (“Button”)
Output

These are the common widgets in the streamlit framework. Let us now implement a Machine Learning project and deploy using the Streamlit framework. We are going to build the machine learning model for Heart disease prediction.
Heart Disease prediction with Machine Learning and deploy using streamlit
Machine Learning is very useful in the medical field to detect many diseases in the early stage. Heart disease prediction is one such Machine Learning model which helps to detect heart disease in humans.
The workflow to build the end to end Machine Learning Project to predict heart disease is as follows
- Collection of data
- Data Preprocessing
- Splitting the data
- Training the model
- Predicting the outcome
- Deploying the model
Data collection
The very first step is to choose the dataset for our model. We can get a lot of different datasets from Kaggle. You just need to sign in to Kaggle and search for any dataset you need for the project. The Heart disease dataset required for our model can be downloaded with the following link.
The Heart Disease dataset contains about 14 columns and the details available in the dataset includes,
- age – age in years
- sex – (1 = male; 0 = female)
- cp – chest pain type (4 values)
- trestbps – resting blood pressure (in mm Hg on admission to the hospital)
- chol – serum cholesterol in mg/dl
- fbs – fasting blood sugar > 120 mg/dl (1 = true; 0 = false)
- restecg – resting electrocardiographic results (values 0,1,2)
- thalach – maximum heart rate achieved
- exang – exercise induced angina (1 = yes; 0 = no)
- oldpeak – ST depression induced by exercise relative to rest
- slope – the slope of the peak exercise ST segment
- ca – number of major vessels (0-3) colored by fluoroscopy
- thal – (0 = normal; 1 = fixed defect; 2 = reversible defect)
- target – 0 or 1
Importing the required libraries
After downloading the dataset, import the necessary libraries required for building the model before you Deploy Machine Learning model using Streamlit
#Importing the libraries
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score
Load the data using the read_csv method in the pandas library
#Loading the data
data = pd.read_csv (‘data.csv’)
The head() method in the pandas library is used to print the rows up to the limit we specify. The default number of rows is five.
#Print the first 5 rows of the dataset
data.head()
Output:

#To get the number of rows and columns in the dataset
data.shape
Output:
(1025, 14)
We can see that there are 1025 rows and 14 columns in the dataset
#Getting information about the data
data.info()
Output:

From the information we collected in the data, we can see that there is no null or missing data in the dataset. And, it is clear that Target is the outcome variable. So let us explore more details about that column.
#Checking the distribution of Target Variable
data[‘target’].value_counts()
Output:
1 526
0 499
Name: target, dtype: int64
In the target column, the value 1 means the person is having Defective Heart and 0 means the person is having Healthy Heart
Splitting the data
The next step in the building of the Machine learning model is splitting the data into training and testing sets. The training and testing data should be split in a ratio of 3:1 for better prediction results.
X = data.drop (columns=’target’, axis=1)
Y = data [‘target’]
print(X)
Output:

print(Y)
Output:

Splitting the Data into Training data & Test Data
X_train, X_test, Y_train, Y_test = train_test_split (X, Y, test_size=0.2, stratify=Y, random_state=2)
print (X.shape, X_train.shape, X_test.shape)
Output:
(1025, 13) (820, 13) (205, 13)
Training the model
The next step is to build and train our model. We are going to use a Logistic regression algorithm to build our model. Logistic Regression is one of the popular supervised Machine Learning algorithms. It is used to predict the outcome of categorical data. Classification problems like Heart disease prediction can be implemented using a Logistic Regression algorithm.
model = LogisticRegression()
# Training the LogisticRegression model with the Training data
model.fit (X_train.values, Y_train)
Model Evaluation
After building the model, the model has to predict output with test data.
# Predicting the output with test data
y_pred=model.predict (X_test.values)
print (y_pred)
Output:

After the prediction of outcome with test data, we can calculate the accuracy score of the prediction results by the model.
#Calculating the accuracy of the predicted outcome
print (accuracy_score (Y_test,y_pred))
Output:
0.8048780487804879
Building a Predictive System
input_data = (62, 0, 0, 140, 268, 0, 0, 160, 0, 3.6, 0, 2, 2)
# Change the input data to a numpy array
numpy_data= np.asarray (input_data)
# reshape the numpy array as we are predicting for only on instance
input_reshaped = numpy_data.reshape (1,-1)
prediction = model.predict (input_reshaped)
if (prediction[0]== 0):
print (‘The Person does not have a Heart Disease’)
else:
print (‘The Person has Heart Disease’)
Output:
The Person does not have a Heart Disease
#Saving the trained model
import pickle
filename = ‘trained_model.sav’
#dump=save your trained model
pickle.dump (model,open (filename,’wb’))
#loading the saved model
loaded_model = pickle.load (open (‘trained_model.sav’,’rb’))
Once you run this code a new file named trained_model.sav will be saved the project folder.
Python Code to Deploy Machine Learning model using Streamlit
Open a new Python file and execute the following code.
App.py
#Importing the libraries
import numpy as np
import pickle
import streamlit as st
#loading the saved model
loaded_model = pickle.load (open (“C:/Downloads/trained_model.sav”, ‘rb’))
#Creating a function for Prediction
def heartdisease_prediction (input_data):
# changing the input data to a numpy array
numpy_data= np.asarray (input_data)
#Reshaping the numpy array as we are predicting for only on instance
input_reshaped = numpy_data.reshape (1,-1)
prediction = loaded_model.predict (input_reshaped)
if (prediction[0] == 0):
st.success (‘The person does not have heart disease’)
else:
st.warning (‘The person have heart disease’)
#Adding title to the page
st.title (‘Heart disease prediction Web App’)
#Getting the input data from the user
age = st.text_input (‘Age in Years’)
sex = st.text_input (‘Sex : 1 – male, 0 – female’)
cp = st.text_input (‘Chest pain type’)
trestbps = st.text_input (‘Resting blood pressure in mm Hg’)
chol = st.text_input (‘Serum cholesterol in mg/dl’)
fbs = st.text_input (‘Fasting blood sugar > 120 mg/dl : 1 – true, 0 – false’)
restecg = st.text_input (‘Resting electrocardiographic results’)
thalach = st.text_input (‘Maximum heart rate achieved’)
exang = st.text_input (‘Exercise induced angina: 1 – yes, 0 – no’)
oldpeak = st.text_input (‘ST depression’)
slope = st.text_input (‘Slope’)
ca = st.text_input (‘Number of major vessels (0-3)’)
thal = st.text_input (‘Thal’)
# code for Prediction
diagnosis = ‘ ‘
# creating a button for Prediction
if st.button (‘Heart Disease Test Result’):
diagnosis=heartdisease_prediction ([age,sex,cp,trestbps,chol,fbs,restecg,thalach,
exang,oldpeak,slope,ca,that])
Save the file after pasting the code. And then to deploy using streamlit go to command prompt run the following command.
streamlit run App.py
(or)
streamlit run filename.py
After running the command the web app will open in the localhost webserver. Otherwise, go to your browser and type localhost:8501. The following output will be shown.
Output:


Sample Input data for person does not have a heart disease is {52, 1, 0, 125, 212, 0, 1, 168, 0, 1, 2, 2, 3}. These data as input will generate the following output in the web app.

Sample input data for a person who have a heart disease is {58, 0, 0, 100, 248, 0, 0, 122, 0, 1, 1, 0, 2}.
These data as input will generate the following output in the web app.

Conclusion
Thus in this article, we learned how to Deploy Machine Learning model using Streamlit. Although Streamlit has many advantages over the other frameworks, lot more features are under development. So if you are getting started in Machine Learning then this framework will be a perfect start to deploy your machine learning model on the web.
Also Read:
- Aam Aadmi vs Corrupt System: How ChatGPT Helped One Guy Expose Govt Fraud, The Story: “Ravi and The Missing Light Pole”
- ChatGPT Asked a person to commit suicide to solve the problem
- Viral Moment: China’s AgiBot X2 Makes History With World’s First Webster Backflip
- Terminator Rising: Albania Hands Power to AI, Echoing a Nightmare of Human Extinction
- What Is Albania’s World-First AI-Generated Minister and How Does It Work?
- Does ChatGPT believe in God? ChatGPT’s Personal Opinion
- ChatGPT vs Human: The Breath-Holding Chat That Ends in “System Failure”
- What Is Vibe Coding? The Future of No-Code Programming and Its Impact on Software Developers
- Struggling to Generate Ghibli-Style AI Images? Here’s the Real Working Tool That Others Won’t Tell You About!
- ChatGPT vs DeepSeek: Who is the winner?
- People are becoming AI Engineer with this free course in 2025: Here is how to join this…
- Apply to Google’s Student Training in Engineering Program (STEP) Intern, 2025
- Self-Driving Car Saves Falling Pedestrian, Showcases Promise of Autonomous Technology
- Instant Karma: Employer Fires Tech Team with AI, Faces Backlash on LinkedIn While Seeking New Developers
- LinkedIn’s COO Reveals the AI Interview Question That Could Land You the Job in 2025
- Elon Musk’s xAI Raises $6 Billion, Valued at $45 Billion
- Google Unveils Veo 2 and Imagen 3: A New Era of AI-Generated Content
- Imagination to Reality, Unlocking the Future: Genesis Physics Engine for 4D Simulation
- Simple Code to compare Speed of Python, Java, and C++?
- Falling Stars Animation on Python.Hub October 2024
- Most Underrated Database Trick | Life-Saving SQL Command
- Python List Methods
- Top 5 Free HTML Resume Templates in 2024 | With Source Code
- How to See Connected Wi-Fi Passwords in Windows?
- 2023 Merry Christmas using Python Turtle



