
There are many methods and libraries to download file from URL using Python and we will try to cover the most used and reliable methods. In this article, we will see 4 console-based methods and one GUI-based app to download file from URL using Python.
The four methods include 4 different libraries:
- urllib -> pip install urllib
- requests -> pip install requests
- wget -> pip install wget
- dload -> pip install dload
Method 1: Using urllib
urllib is the fastest among all methods.
import urllib.request
urllib.request.urlretrieve(url, "filename")You can download any type of file, just give the correct URL and write the filename as you wish.
File will be saved in the same location(folder) where you are running this python program to download file from URL, not for just this method but in all methods, file will be saved where your python script is running.
Method 2: Using requests
import requests
# give correct url
URL = "https://copyassignment.com/wp-content/uploads/2022/11/CopyAssignment-logo-3.png"
response = requests.get(URL)
open("CopyAssignment.png", "wb").write(response.content)Method 3: Using wget
import wget
URL = "https://copyassignment.com/wp-content/uploads/2022/11/CopyAssignment-logo-3.png"
wget.download(URL, "websitelogo.png")Method 4: Using dload
import dload
URL = "https://https://example.com/filename.png"
dload.save(URL)The name of the file will be according to the URL, for example, if the URL is https://example.com/filename.png then the file name will be filename.png
Python GUI App Download File from URL
Now, we will create a Python GUI app using tkinter to download files from URLs.
Design Flow
- Designing a tkinter window consists of widgets to get input from the user.
- Designing utility function: function to download files from URL which can handle all cases for invalid or null URLs.
- Convert the program (.py) to the application (.exe)
How the program will function?
The program will take input of URL and filename (without extension). The filename is optional though. The download function will download the file if the URL is not null and valid. And the success message will be shown. The clear function will clear the entries.
1. Tkinter window
Let’s import modules and define the window, its geometry, and its fonts.
from tkinter import *
from tkinter import messagebox
from PIL import ImageTk, Image
import tkinter.font as font
root = Tk()
root.title("Download File from URL")
icon = PhotoImage(file='icon.png')
root.iconphoto(False,icon)
root.minsize(600,500)
root.maxsize(600,500)
HEIGHT = 500
WIDTH = 500
FONT = font.Font(family ="Comic Sans MS", size ="10", weight ="bold"Let’s design the widgets.
canvas = Canvas(root, height = HEIGHT, width = WIDTH)
canvas.pack()
background_image = ImageTk.PhotoImage(Image.open(r"bg.jpg"))
background_label = Label(root, image = background_image)
background_label.place(relwidth = 1, relheight =1)
frame = Frame(root, bg ="yellow", bd =5)
frame.place(relx = 0.5, rely = 0.1, relwidth = 0.80, relheight = 0.25, anchor = "n")
label_up = Label(frame)
label_up.place( relwidth= 1 , relheight = 1)
label1 = Label(frame, text = "Enter the URL", font =FONT, bd =5, bg ="#fc034e", highlightbackground = "#d9138a", fg = "black")
label1.place(relx = 0.1, rely = 0.1,relwidth = 0.25, relheight =0.25)
label2 = Label(frame, text = "Enter Filename", font =FONT, bd =5, bg ="#fc034e", highlightbackground = "#d9138a", fg = "black")
label2.place(relx = 0.1, rely = 0.64,relwidth = 0.25, relheight =0.25)
entry1= Entry(frame, font = FONT, fg = "#001a4d")
entry1.place(relx = 0.54, rely = 0.1, relwidth=0.4, relheight = 0.25)
entry2= Entry(frame, font = FONT, fg = "#001a4d")
entry2.place(relx = 0.54, rely = 0.64, relwidth=0.4, relheight = 0.25)
button1 = Button(root, text = "DOWNLOAD", font = FONT, bg = "pink", fg = "black", activeforeground = "pink", activebackground = "black", command = lambda:download(entry1.get(),entry2.get()))
button1.place(relx = 0.25,rely = 0.4,relwidth = 0.19, relheight = 0.07)
button2 = Button(root, text = "CLEAR", font = FONT, bg = "pink", fg = "black", activeforeground = "pink", activebackground = "black", command = clear)
button2.place(relx = 0.55,rely = 0.4,relwidth = 0.19, relheight = 0.07)
lower_frame = Frame(root, bg ="yellow", bd =10)
lower_frame.place(relx = 0.5, rely = 0.53, relwidth = 0.8, relheight = 0.25, anchor = "n")
label_down = Label(lower_frame, font = FONT, fg = "#001a4d", anchor = "nw", justify = "left", bd =4)
label_down.place( relwidth=1, relheight = 1)
root.mainloop()The background image and icon image are as follows:

Let’s code the buttons download() and clear().
2. Coding utility function (main logic):
Basically, all we have to do is to fetch the inputted URL and search it and download the contents to a file.
When the thing is about URLs or websites, the Python module majorly comes to play in requests.
We will be going to use a request to get a response from the inputted URL and if it is valid, write the contents present on that URL to a file.
For downloading the file from the URL, the code is of simple 2 lines.
import requests
import re
response = requests.get(URL,allow_redirects=True)
open(filename,"wb").write(response.content)Observe in the code snippet above, requests first fetch the content from the URL, and then the content is jotted down in a file and hence downloaded. Note that the filename used here is including the file extension.
We are designing a fully dynamic, user-functional program and hence we might don’t know what is the filename.
Now, here comes 2 things: how to check if the URL is valid, and second what should be the filename.
One interesting utility attached to our response object is it can give full details of the URL by the following command
print(response.headers)From here we can check if our content is of which type, length of the content, size, etc. For eg.
r=requests.get("https://www.google.com/",allow_redirects=True)
print(r.headers)Output:
{'Date': 'Sun, 08 Jan 2023 05:43:23 GMT', 'Expires': '-1', 'Cache-Control': 'private, max-age=0', 'Content-Type': 'text/html; charset=ISO-8859-1', 'Cross-Origin-Opener-Policy-Report-Only': 'same-origin-allow-popups; report-to="gws"', 'Report-To': '{"group":"gws","max_age":2592000,"endpoints":[{"url":"https://csp.withgoogle.com/csp/report-to/gws/other"}]}', 'P3P': 'CP="This is not a P3P policy! See g.co/p3phelp for more info."', 'Content-Encoding': 'gzip', 'Server': 'gws', 'X-XSS-Protection': '0', 'X-Frame-Options': 'SAMEORIGIN', 'Set-Cookie': '1P_JAR=2023-01-08-05; expires=Tue, 07-Feb-2023 05:43:23 GMT; path=/; domain=.google.com; Secure, AEC=ARSKqsJILFHppqTme0McLyPB5iUbvR3W0uvzcP0rgcGYLGkM1OqWRsXgRHM; expires=Fri, 07-Jul-2023 05:43:23 GMT; path=/; domain=.google.com; Secure; HttpOnly; SameSite=lax, NID=511=fGI9MYpmQfjGxt1vvGxIfqz-Xg8ZCkucm404WQ7NDxkUsHR8zJ8qcQkwjPc2kmysQXoRzxHE9MyXj1frxeuCpfDkznqlAbKTZzF5pH24kE9VXUlLh5jVmkt9zXBq6Y7F3-fwImlbL2_ON5ULZw9rgKGQ0znVgV1-z8sb68aDj2g; expires=Mon, 10-Jul-2023 05:43:23 GMT; path=/; domain=.google.com; HttpOnly', 'Alt-Svc': 'h3=":443"; ma=2592000,h3-29=":443"; ma=2592000,h3-Q050=":443"; ma=2592000,h3-Q046=":443"; ma=2592000,h3-Q043=":443"; ma=2592000,quic=":443"; ma=2592000; v="46,43"', 'Transfer-Encoding': 'chunked'}We are using only one key from this dictionary.
print(r.headers['content-type']
#output
text/html; charset=ISO-8859-1Our program will not be going to download as it is HTML. Note that the file extension here is after ‘/’.
This is a very useful function to validate if it is text or HTML, so we can term it as Un-Downloadable.
We are taking the filename (without extension) as input. And as we have discussed it is not a compulsory parameter. And hence if the filename is not given as an input, we will fetch it using the os module as,
a = urlparse(url)
name = os.path.basename(a.path)These are the main heroes of our program. We just need to assemble them into function. We are designing 2 functions from it.
Import the libraries:
import requests
import re
import validators
import os
from urllib.parse import urlparse1. download(): This function takes 2 inputs: URL and filename (optional).
We will have 2 cases to test:
1. if the URL is not valid.
2. if the URL is empty.
Error messages will be thrown if any of the cases is True. If all of the 2 are False, the else part will check if the URL can be downloaded or not. If so, the file will be downloaded and the success message will be shown on the down label.
Let’s design this function.
def download(url,name):
valid=validators.url(url)
#if the url is valid
if(valid!=True):
messagebox.showerror("Invalid URL", "URL is invalid")
#if the url is empty
elif(url==""):
messagebox.showerror("No valid URL", "URL cannot be empty")
else:
response = requests.get(url,allow_redirects=True)
rhead=response.headers['Content-Type']
#if the url is downloadable
if(canbedownloaded(rhead)):
if(name==""):
a = urlparse(url)
name = os.path.basename(a.path)
file_data=rhead.split('/')
ext=file_data[1]
filename=name+'.'+ext
open(filename, "wb").write(response.content)
label_down['text'] = f"Your file {filename}\n has been downloaded successfully."
else:
label_down['text']= "This file is invalid. It can not be downloaded."This is just the work of assembling. Now let’s design the next function.
2. canbedownloaded(): this function takes the ‘content-type’ information and returns a flag if the content is of type text or HTML.
def canbedownloaded(rhead):
if 'text' in rhead.lower():
return False
if 'html' in rhead.lower():
return False
return TrueAlso, we have added one button to clear both of the entries. The following function will do that task.
def clear():
entry1.delete(0,END)
entry2.delete(0,END)
label_down['text'] = ""Complete code for Python GUI App Download File from URL
from tkinter import *
from tkinter import messagebox
from PIL import ImageTk, Image
import tkinter.font as font
import requests
import re
import validators
import os
from urllib.parse import urlparse
root = Tk()
root.title("Download File from URL")
icon = PhotoImage(file='icon.png')
root.iconphoto(False, icon)
root.minsize(600, 500)
root.maxsize(600, 500)
HEIGHT = 500
WIDTH = 500
FONT = font.Font(family="Comic Sans MS", size="10", weight="bold")
canvas = Canvas(root, height=HEIGHT, width=WIDTH)
canvas.pack()
background_image = ImageTk.PhotoImage(
Image.open(r"bg.jpg"))
background_label = Label(root, image=background_image)
background_label.place(relwidth=1, relheight=1)
frame = Frame(root, bg="yellow", bd=5)
frame.place(relx=0.5, rely=0.1, relwidth=0.80, relheight=0.25, anchor="n")
label_up = Label(frame)
label_up.place(relwidth=1, relheight=1)
label1 = Label(frame, text="Enter the URL", font=FONT, bd=5,
bg="#fc034e", highlightbackground="#d9138a", fg="black")
label1.place(relx=0.1, rely=0.1, relwidth=0.25, relheight=0.25)
label2 = Label(frame, text="Enter Filename", font=FONT, bd=5,
bg="#fc034e", highlightbackground="#d9138a", fg="black")
label2.place(relx=0.1, rely=0.64, relwidth=0.25, relheight=0.25)
entry1 = Entry(frame, font=FONT, fg="#001a4d")
entry1.place(relx=0.54, rely=0.1, relwidth=0.4, relheight=0.25)
entry2 = Entry(frame, font=FONT, fg="#001a4d")
entry2.place(relx=0.54, rely=0.64, relwidth=0.4, relheight=0.25)
def download(url, name):
valid = validators.url(url)
# if the url is valid
if (valid != True):
messagebox.showerror("Invalid URL", "URL is invalid")
# if the url is empty
elif (url == ""):
messagebox.showerror("No valid URL", "URL cannot be empty")
else:
response = requests.get(url, allow_redirects=True)
rhead = response.headers['Content-Type']
# if the url is downloadable
if (canbedownloaded(rhead)):
if (name == ""):
a = urlparse(url)
name = os.path.basename(a.path)
file_data = rhead.split('/')
ext = file_data[1]
filename = name+'.'+ext
open(filename, "wb").write(response.content)
label_down['text'] = f"Your file {filename}\n has been downloaded successfully."
else:
label_down['text'] = "This file is invalid. It can not be downloaded."
def canbedownloaded(rhead):
if 'text' in rhead.lower():
return False
if 'html' in rhead.lower():
return False
return True
def clear():
entry1.delete(0, END)
entry2.delete(0, END)
label_down['text'] = ""
button1 = Button(root, text="DOWNLOAD", font=FONT, bg="pink", fg="black", activeforeground="pink",
activebackground="black", command=lambda: download(entry1.get(), entry2.get()))
button1.place(relx=0.25, rely=0.4, relwidth=0.19, relheight=0.07)
button2 = Button(root, text="CLEAR", font=FONT, bg="pink", fg="black",
activeforeground="pink", activebackground="black", command=clear)
button2.place(relx=0.55, rely=0.4, relwidth=0.19, relheight=0.07)
lower_frame = Frame(root, bg="yellow", bd=10)
lower_frame.place(relx=0.5, rely=0.53, relwidth=0.8,
relheight=0.25, anchor="n")
label_down = Label(lower_frame, font=FONT, fg="#001a4d",
anchor="nw", justify="left", bd=4)
label_down.place(relwidth=1, relheight=1)
root.mainloop()Output for Python GUI App Download File from URL
Image output:
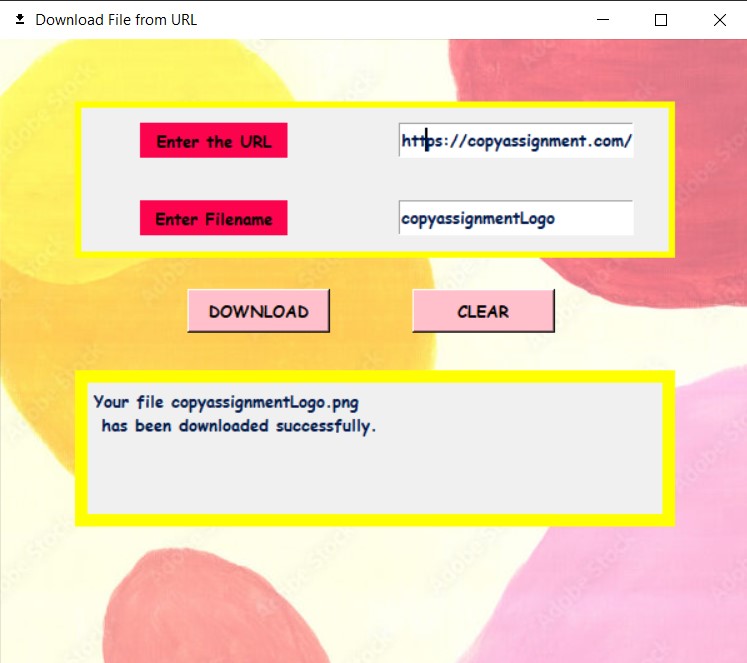
Video output:
We hope this article on Download File from URL using Python helped you. Thank you for visiting our website.
Also Read:
- Create your own ChatGPT with Python
- SQLite | CRUD Operations in Python
- Event Management System Project in Python
- Ticket Booking and Management in Python
- Hostel Management System Project in Python
- Sales Management System Project in Python
- Bank Management System Project in C++
- Python Download File from URL | 4 Methods
- Python Programming Examples | Fundamental Programs in Python
- Spell Checker in Python
- Portfolio Management System in Python
- Stickman Game in Python
- Contact Book project in Python
- Loan Management System Project in Python
- Cab Booking System in Python
- Brick Breaker Game in Python
- Tank game in Python
- GUI Piano in Python
- Ludo Game in Python
- Rock Paper Scissors Game in Python
- Snake and Ladder Game in Python
- Puzzle Game in Python
- Medical Store Management System Project in Python
- Creating Dino Game in Python
- Tic Tac Toe Game in Python
- Test Typing Speed using Python App
- Scientific Calculator in Python
- GUI To-Do List App in Python Tkinter
- Scientific Calculator in Python using Tkinter
- GUI Chat Application in Python Tkinter


