
Have you come across products on Amazon that is recommended to you or videos on YouTube or how Facebook or LinkedIn recommends new friend/connections? Of course, you must on daily basis. All of these recommendations are nothing but the Machine Learning algorithms forming a system, a recommendation system. Recommendation systems recommend relevant items or content to a user based on his/her past activity or interests.
These systems are really powerful and currently widely used in almost every e-commerce website or OTT or social media app.
Movie Recommendation System and its types:
Movie recommendation systems are recommendation systems recommending movies to a person based on their past data or activities. There are 3 types of recommendation systems:
- Content-based: This system is based upon the similarity of movie attributes. For eg., if a user has watched the ‘XYZ’ actor’s movie then the system will recommend the user that specific actor’s movie. These attributes can be anything like cast, crew, director, movie category, etc. Based on the similarity score between the attributes the system will recommend the movies.
- Collaborative filtering: This system is based on the interaction between the movies and users. Based upon the activities of 2 or more users, it will recommend the movies to the next user. For eg. If user1 watched ‘XYZ’, ‘ABC’ and ‘PQR’ movies and user2 watched ‘ABC’, ‘PQR’, and ‘LMN’ movies then, if the user3 is watching ‘PQR’, the system will recommend the ‘ABC’ movie to the user.
- Hybrid: Hybrid is a combination of both, content-based and collaborative filtering-based movie recommendation systems.
In this project, we are discussing the movie recommendation system keeping the basis as content. The content will be the cast, director, category, and movie description which will be combined and the ML model will be built. Also, we are making this project as a web app hosted on localhost with the help of streamlit.
Let’s start:
Dataset
The dataset that we are using here is the TMDB 5000 Movie Dataset. Under this dataset, there are 2 files:
1. tmdb_5000_movies.csv: It includes 20 columns like budget, genres, id, keywords, title, tagline, etc.
2. tmdb_5000_credtis.csv: It includes 4 columns- movie_id, title, cast, and crew.
We are using both of these datasets. You can download both of the datasets from here.
Now, let’s process the data and build our mode. You can use jupyter notebook or google collab or any corresponding ide.
Data Processing
Let’s import the datasets into the collaboratory or at ide. Here, for eg. in google collab under the file section files are uploaded. In jypyter simply upload the file in the same folder as the ipynb.

The two main libraries we are using here are pandas and numpy, make sure you have them. In case you don’t install using:
pip install pandas
pip install numpyImport the libraries:
import numpy as np
import pandas as pdRead the data:
movies = pd.read_csv('tmdb_5000_movies.csv')
credits = pd.read_csv('tmdb_5000_credits.csv')pandas library provides the read_csv() method which reads the CSV file and converts it into the dataframe.
View the data:
Let’s check what we have in our movies and credits data frames.
movies.head(1)

The head() function returns the specified number of rows and by default the first 5 rows.
From this dataframe, we need genres (to recommend movies on the basis of category), id (to fetch images in the web app), keywords, overview (movie description), and title.
Next,
credits.head(1)
Here, we’ll need the cast (actors) and crew (director).
But these are 2 different datasets. We need to merge them to ease the model making. We can see there are 2 columns similar in both of the datasets, ‘movie_id’ and ‘title’.
Let’s merge them on the basis of ‘title’ and see if it really merged.
Merging the datasets:
movies = movies.merge(credits,on='title')
movies.head(1)

Now there is a total of 23 columns formed by merging 19 and 3 columns on 1 column.
Here, in the dataframe we have 23 columns and which are absolutely unnecessary. As we have discussed earlier what columns we’ll need, we will remove the unimportant ones.
Remove unnecessary columns:
movies = movies[['id','title','overview','genres','keywords','cast','crew']]
movies.head(1)
This is our main data. We will build our model on the basis of these columns.
But still, for the content-based recommender, we need everything i.e. on what basis we are building in one single column. Let’s say that column is called ‘tags’. Hence, we need to convert the ‘overview’, ‘genres’, ‘keywords’, ‘cast’ and ‘crew’ in one single column as ‘tags’. But the datatypes of these columns is not similar to each other. Hence, first, we need to convert them into text and merge these texts together.
Let’s do that.
Check and Remove Missing data:
movies.isnull().sum()
There are 3 missing values in the overview. Let’s drop them.
movies.dropna(inplace=True)After dropping, let’s check if they are really removed or not.
movies.isnull().sum()
Voila! They are not in our data anymore.
Check for Duplicate data:
movies.duplicated().sum()
This is now done. As we have discussed, we need to convert the columns into a unified format and then merge them.
Preprocess ‘genres’:
Let’s first see exactly how our ‘genres’ is.
movies.iloc[0].genres
This data is the list of dictionaries. We need to convert this list of dictionaries to a list of names, for eg. here as [‘Action’, ‘Adventure’, ‘Fantasy’, ‘Science Fiction]. Now, how do we do that?
But first, this list of dictionaries is actually a string. We need to remove that string format otherwise our function won’t work for separating the names of the genres.
For the same, we will use the ‘ast’ module’s literal_eval() function. Let’s see how this function works first.
If we pass the above string of list of dictionaries in the function, we get:
import ast
ast.literal_eval('[{"id": 28, "name": "Action"}, {"id": 12, "name": "Adventure"}, {"id": 14, "name": "Fantasy"}, {"id": 878, "name": "Science Fiction"}]')
Have you seen it? How powerfully it removed that string of quotes.
Now, let’s use this function and write a helper function for our main aim, i.e. to convert into the list of names.
def convert(obj):
L = []
for i in ast.literal_eval(obj):
L.append(i['name'])
return LThis is a simple python code where we are iterating over each dictionary and extracting only the name in it. Now apply this to whole ‘genres’.
movies['genres'].apply(convert)
And it’s done. It is clearly converted into the desired format! Let’s now store this change in the same column.
movies['genres'] = movies['genres'].apply(convert)Preprocess ‘keywords’:
We’ll apply the same function for ‘keywords’.
movies['keywords'] = movies['keywords'].apply(convert)
movies.head(1)
Hence, ‘keywords’ is also converted.
Preprocess ‘cast’:
Let’s first see what our ‘cast’ actually contains:
movies['cast'][0]
We have this much amount of value in here. But we just need the top 3 actors’ names, i.e.

How do we do that? We’ll use the same ‘convert’ function and set a counter for 3 values.
def convert3(obj):
L = []
c=0
for i in ast.literal_eval(obj):
if(c!=3):
L.append(i['name'])
c+=1
else:
break
return L
movies['cast'] = movies['cast'].apply(convert3)movies['cast']
The ‘cast’ column is also processed.
Preprocessing for ‘crew’:
movies['crew'][0]
‘crew’ contains a list of dictionaries with details of the job of crew members. We need the ‘director’ name from this data, hence we need to extract the job ‘Director’.

How do we do that? We’ll use similar code with added logic.
def fetchDirector(obj):
L = []
for i in ast.literal_eval(obj):
if(i['job']=='Director'):
L.append(i['name'])
break
return L
movies['crew'] = movies['crew'].apply(fetchDirector)movies['crew']
‘crew’ has been also formatted.
Preprocess for ‘overview’:
movies['overview'][0]
‘overview’ is actually a string and all other columns are lists. Hence, we will convert the string to the list.
How do we do that? We’ll just split the strings.
movies['overview'] = movies['overview'].apply(lambda x:x.split())
movies['overview][0]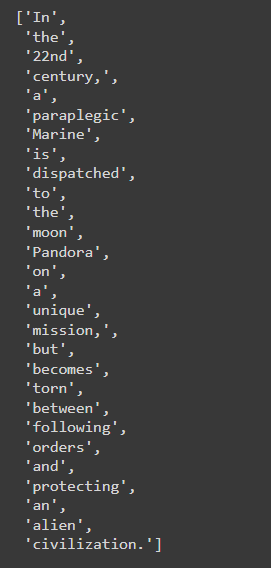
Now that all is done, the only left is to concatenate the above-preprocessed columns into single ‘tags’ (as we have discussed) and then convert this concatenated list to a string to become a paragraph.
But the problem is in the columns ‘keywords’, ‘cast’, and ‘crew’, the content is separated by white spaces and we don’t want them to scatter while we concatenate and build our model otherwise it will lead to low efficiency.
for eg., two people might have the same first name, here in the case of ‘Sam Wothington’ and ‘Sam Mendes’. We don’t want our model to confused and recommended wrong.
movies.head(1)
How do we do that? We’ll just replace the ” ” with “” for every column.
movies['genres'] = movies['genres'].apply(lambda x:[i.replace(" ","") for i in x])
movies['keywords'] = movies['keywords'].apply(lambda x:[i.replace(" ","") for i in x])
movies['cast'] = movies['cast'].apply(lambda x:[i.replace(" ","") for i in x])
movies['crew'] = movies['crew'].apply(lambda x:[i.replace(" ","") for i in x])movies.head()
Done! We are almost there to process our data.
Concatenating the columns into one ‘tags’:
movies['tags'] = movies['overview'] + movies['genres'] + movies['cast'] + movies['crew']
movies.head()
Here, we can see that the new ‘tags’ have been created.
Now our new dataframe will only contain 3 columns: ‘id’, ‘title’, ‘tags’.
new_df = movies[['id','title','tags']]
new_df.head()
This is what we want. Now the ‘tags’ should be a paragraph, i.e. a string to make it understood by our model. Let’s convert it.
new_df['tags'] = new_df['tags'].apply(lambda x: " ".join(x))After the run of the above code, you might get a warning for a copy. You can ignore it.
new_df['tags'][0]![new_df['tags'][0] Movie Recommendation System: with Streamlit and Python-ML](https://copyassignment.com/wp-content/uploads/2022/07/image-134-1024x32.png)
It is best practice to convert this into lower case alphabets and the paragraph is now done.
new_df['tags'] = new_df['tags'].apply(lambda x:x.lower())
new_df['tags'][0]
Data processing is done.
Building the model
Here, is what we are gonna actually do, we are recommending the user based upon these ‘tags’. Now how we will know that these 5 movies are similar? We will find similarities between the tags of the two movies. Manually it is difficult to calculate similar words between two movies and in other words, it is inefficient.
Hence here we will vectorize each of the ‘tags’. And we will find similarities between them by finding similarities in the text. The 5 nearest vectors will be the answer for each vector.
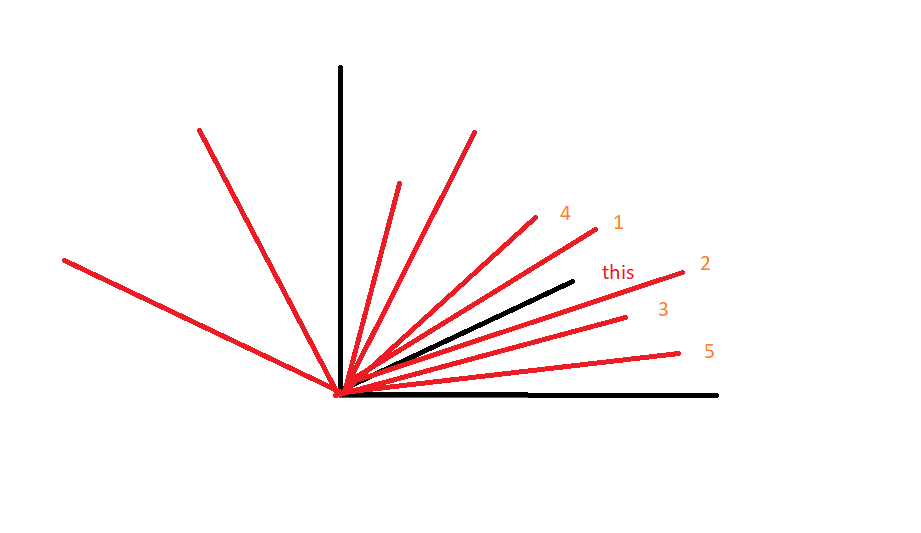
For eg. in the above figure, consider each line as each ‘tag’ in 2D space, and the nearest 5 vectors here are the 5 similar movies.
What is Vectorization?
Vectorization is jargon for a classic approach of converting input data from its raw format (i.e. text ) into vectors of real numbers which is the format that ML models support. This approach has been there ever since computers were first built, it has worked wonderfully across various domains, and it’s now used in NLP.
In Machine Learning, vectorization is a step in feature extraction. The idea is to get some distinct features out of the text for the model to train on, by converting text to numerical vectors.
Vectorization Techniques:
- Bag of Words
- TF-IDF
- Word2Vec
- GloVe
- FastText
For more info, read here.
We are using the ‘Bag of Words’ technique in our project.
How we are using ‘Bag of Words‘?
We will combine each of the tags to form a large text. And from this text, we will calculate 5000 most frequent words. Then, for every word, we will calculate its frequency with each of the rows in ‘tags’. These frequency rows are nothing but vectors in 5000×5000 geometry space. (5000 – no. of words and 5000 – no. of movies)
For eg.
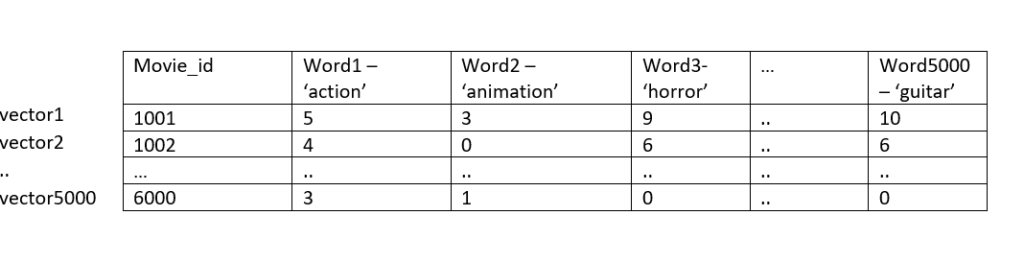
Each of the vectors will plot against each with words as axes and most similar vectors will be considered as the result.
For eg. if we consider 2 words then the space will be 5000×2, for understanding, we can plot the graph.
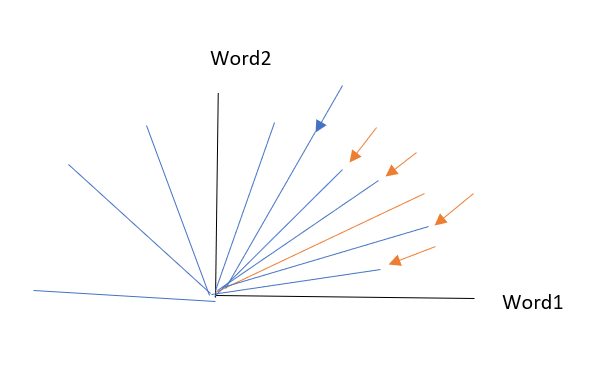
Before performing vectorization, stop words must be removed. Stop words are words useful in constructing the sentence for eg. and, or, to, is, etc.
For vectorization, we will use scikit-learn. In case you don’t have this module, you can install using:
pip install scikit-learnThis module has CountVectorizer class for performing vectorization. For more info, read here.
from sklearn.feature_extraction.text import CountVectorizer
cv = CountVectorizer(max_features=5000, stop_words='english')Parameters taken are max_features is the number of words and stop_words in English to remove them.
Now, let’s convert it into a vector using the ‘cv’ object.
vectors = cv.fit_transform(new_df['tags']).toarray()
vectorsfit_transform() returns a scikit sparse matrix, hence it is necessary to convert it into an np array.
This is a sparse matrix, vectors.
We can actually get these 5000 words or feature names.
cv.get_feature_names()
These words also contain numbers or years that are most frequent.
Now, this feature contains similar words in a different form. For eg. accident, accidentally, and accidental are the same words. We need to fix this issue. For this, we’ll use stemming from NLTK. To install nltk, you can follow:
pip install nltkimport nltk
from nltk.stem.porter import PorterStemmer
ps = PorterStemmer()PorterStemmer’s class removes commoner morphological and inflexional endings from words in English.v Let’s take a look at what it actually does.
ps.stem('called')
#output:
callWe’ll use this functionality on our feature names.
def stem(text):
y = []
for i in text.split():
y.append(ps.stem(i))
return " ".join(y)new_df['tags'] = new_df['tags'].apply(stem)
Now, our stemming is done. You can simply run the cells from scikit import till above for unrepeated words.
After running the vectorizer, feature names can be found correct.
Now, for the next step we have a total of 4806 movies and every movie is a vector. Now, we will calculate the distance between every movie for movie. This distance is not Euclidean’s distance, but this will be the cosine angle between the two movies. Lesser the distance, the more the similarity between them. This distance is nothing but the cosine similarity. Sklearn has a function to calculate this similarity.
from sklearn.metrics.pairwise import cosine_similarity
cosine_similarity(vectors)
Here, you can see the similarity of every movie with every movie. Look that the similarity of a movie with itself is 1.00. The similarity diagonally will always 1.
If we try to figure out the shape of this similarity, we will get: 4806,4806 i.e. similarity is calculated for every movie with every other movie.
similarity = cosine_similarity(vectors).shape
#output
(4806,4806)For eg., if we want to see similarity score of the first movie with all movies, I can simply run the code as:
similarity[0]
Now, we’ll design a function to recommend the movies.
How do we design it? First, we will find the similarity vector of the movie provided in the input. Then we’ll sort these numbers in increasing order and display the top 5 movies out of corresponding similarity scores.
How do we find the index of the movie? This is how:
movie_index = new_df[new_df['title']==movie].index[0]How do we sort the vector? There’s a problem with sorting. While sorting, the similarity score of the movies will be scattered and we don’t want them because they are crucial in finding the index of the movie. Hence, we will index them using enumerate() and sort them according to the similarity scores.
distances = similarity[movie_index]
movies_list = sorted(list(enumerate(distances)),reverse=True,key=lambda x:x[1])[The ‘key’ parameter specifies according to what we have to sort the data.
Now, let’s write the full function.
def recommend(movie):
#find the index of the movies
movie_index = new_df[new_df['title']==movie].index[0]
distances = similarity[movie_index]
movies_list = sorted(list(enumerate(distances)),reverse=True,key=lambda x:x[1])[1:6]
#to fetch movies from indeces
for i in movies_list:
print(new_df.iloc[i[0]].title)As we need only need 5 movies to recommend, hence slicing is used. Remember we need to neglect the first score as it will be the similarity to itself. Let’s run and check:
recommend('Avatar')
Let’s try for another movie.
recommend('Twilight')
Now, our project is ready.
We are almost there. Just needed to convert it into a web app.
Integrating movie recommendation system with Streamlit
For this, you need to open any python IDE and create a virtual environment.

Use the virtual environment and create an ‘app.py’ file.
What is streamlit? How to install it?
Streamlit is an open-source Python library that makes it easy to create and share beautiful, custom web apps for machine learning and data science. In just a few minutes you can build and deploy powerful data apps.
To install streamlit, type the following command into your cmd:
pip install streamlitFor more info, visit documentation: https://docs.streamlit.io
Create streamlit model
Inside the app.py file, import streamlit first and start with the code.
import streamlit as st
st.title('Movie Recommender System')Now, to run the streamlit app, go to cmd with the current location and type:
streamlit run filename.pyOn your local host, the app will be deployed.

You can check your default browser and can see that it’s actually working.
Now, we need to integrate our ipynb file with py. We’ll need our implemented model and list of movies also. That’s where pickle comes in.
What is pickle?
Python pickle module is used for serializing and de-serializing python object structures. The process to convert any kind of python object (list, dict, etc.) into byte streams (0s and 1s) is called pickling or serialization or flattening or marshaling. For more info, read here.
Dump the file using pickle into your ipynb:
import pickle
pickle.dump(new_df.to_dict(),open('movies.pkl','wb'))Here, we have dumped our dictionary of new dataframe for the movies list. (This is because pandas don’t allow pickling the dataframe, hence it is necessary to convert it into a dictionary here) Now if you refresh, at the same location where your datasets are, you will see a movies.pkl file. Download it and paste it into your working directory of streamlit project.
We need to create a selectbox widget from streamlit to enable users to select the movies.
We need to pass movie names into this selectbox to have movies as options.
import streamlit as st
import pickle
import pandas as pd
movies_dict = pickle.load(open('movies.pkl','rb'))
movies = pd.DataFrame(movies_dict)
st.title('Movie Recommender System')
selected_movie_name = st.selectbox(
"Type or select a movie from the dropdown",
movies['title'].values
)This will create a selectbox of movie names, you can view the output on the browser.
Now, let’s create a button. After clicking on the button, we need to recommend the movies, i.e. we want similarity scores. Let’s dump similarity too.
pickle.dump(similarity,open('similarity.pkl','wb'))Same as previous, download ‘similarity.pkl’ and paste it into the working directory.
Now, using streamlit syntax we are creating a button that recommends the movies on clicking.
similarity = pickle.load(open('similarity.pkl','rb'))
def recommend(movie):
movie_index = movies[movies['title'] == movie].index[0]
distances = similarity[movie_index]
movies_list = sorted(list(enumerate(distances)), reverse=True, key=lambda x: x[1])[1:6]
recommended_movies = []
for i in movies_list:
recommended_movies.append(movies.iloc[i[0]].title)
return recommended_movies
if st.button('Show Recommendation'):
recommendations = recommend(selected_movie_name)
for i in recommendations:
st.write(i)This will write the movies on our page.
Now, we also need movie posters to be seen.
For movie posters, you need to create an account at https://www.themoviedb.org/.

In case you have an existing account, you just need to log in or else click on Join TMDB and fill in the details to create a free account.
Then, go to your profile->click on settings.


If you are a new customer, you need to generate the API key. It’s a very simple step. Just fill in the purpose you want this key for, enter the required details and generate. After successful generation, you’ll see your API key under the API section.

An API key is different and unique for every user. Now, that we have our API key, we can place a request to API to fetch posters for us. URL for posters is given in the documentation of TMDB itself. You can read it here.
The URL is “https://api.themoviedb.org/3/movie/{MOVIE_ID}?{API_KEY}&language=en-US” and image URL is “https://image.tmdb.org/t/p/w500/{MOVIE_POSTER_NAME}”. It may look less readable but it’s super simple.
We need to add the required movieid and our API key to request the data. This data returned will contain details of movie posters, title, ratings, cast, crew, and everything we had in our dataset so far, more than that actually! From this .json data, we will fetch the poster path to request the movie poster.
Now, let’s design a function that grabs this poster. Also, we, want our app to show movie posters and movie names in a row with 5 columns in it. Hence, we’ll call this function from recommended function itself.
Let’s first design a poster function:
import requests
def fetch_poster(movie_id):
url = "https://api.themoviedb.org/3/movie/{}?api_key='Your API Key'&language=en-US".format(movie_id)
data = requests.get(url)
data = data.json()
poster_path = data['poster_path']
full_path = "https://image.tmdb.org/t/p/w500/" + poster_path
return full_pathAs we discussed earlier, let’s now integrate this with recommend function, and also let’s add 5 columns to display the poster streamlit.
Complete code for Movie Recommendation system in Python using Streamlit
import streamlit as st
import pickle
import pandas as pd
import requests
st.title('Movie Recommender System')
def fetch_poster(movie_id):
url = "https://api.themoviedb.org/3/movie/{}?api_key='YOUR API KEY'&language=en-US".format(movie_id)
data = requests.get(url)
data = data.json()
poster_path = data['poster_path']
full_path = "https://image.tmdb.org/t/p/w500/" + poster_path
return full_path
def recommend(movie):
movie_index = movies[movies['title'] == movie].index[0]
distances = similarity[movie_index]
movies_list = sorted(list(enumerate(distances)), reverse=True, key=lambda x: x[1])[1:6]
recommended_movies = []
recommended_movie_posters = []
for i in movies_list:
# fetch the movie poster
movie_id = movies.iloc[i[0]].id
recommended_movies.append(movies.iloc[i[0]].title)
recommended_movie_posters.append(fetch_poster(movie_id))
return recommended_movies,recommended_movie_posters
movies_dict = pickle.load(open('movies.pkl','rb'))
movies = pd.DataFrame(movies_dict)
similarity = pickle.load(open('similarity.pkl','rb'))
selected_movie_name = st.selectbox(
"Type or select a movie from the dropdown",
movies['title'].values
)
if st.button('Show Recommendation'):
names,posters = recommend(selected_movie_name)
#display with the columns
col1, col2, col3, col4, col5 = st.columns(5)
with col1:
st.text(names[0])
st.image(posters[0])
with col2:
st.text(names[1])
st.image(posters[1])
with col3:
st.text(names[2])
st.image(posters[2])
with col4:
st.text(names[3])
st.image(posters[3])
with col5:
st.text(names[4])
st.image(posters[4])Enter your API key here and see the magic. The code is super simple. We just integrate the recommended function with the fetch poster and are done! Now, let’s see the final output.
To run the app, from your current working directory, open the terminal and type:
streamlit run filename.pyLet’s run:
That’s it! Noticed how we can beautifully deploy our ML model?
Streamlit is very useful in showcasing our ML models visually. You can always read streamlit documentation and check for its other features too. It’s like a GUI for ML and data science.
Also, you can get a video explanation of this project here:
I Hope, this was informative! Thank you for sticking here.
Thank you for reading this article, click here to start learning Python in 2022.
Also Read:
- Flower classification using CNN
- Music Recommendation System in Machine Learning
- Top 15 Machine Learning Projects in Python with source code
- Gender Recognition by Voice using Python
- Top 15 Python Libraries For Data Science in 2022
- Top 15 Python Libraries For Machine Learning in 2022
- Setup and Run Machine Learning in Visual Studio Code
- Diabetes prediction using Machine Learning
- 15 Deep Learning Projects for Final year
- Machine Learning Scenario-Based Questions
- Customer Behaviour Analysis – Machine Learning and Python
- NxNxN Matrix in Python 3
- 3 V’s of Big data
- Naive Bayes in Machine Learning
- Automate Data Mining With Python
- Support Vector Machine(SVM) in Machine Learning
- Convert ipynb to Python
- Data Science Projects for Final Year
- Multiclass Classification in Machine Learning
- Movie Recommendation System: with Streamlit and Python-ML
- Getting Started with Seaborn: Install, Import, and Usage
- List of Machine Learning Algorithms
- Recommendation engine in Machine Learning
- Machine Learning Projects for Final Year
- ML Systems
- Python Derivative Calculator
- Mathematics for Machine Learning
- Data Science Homework Help – Get The Assistance You Need
- How to Ace Your Machine Learning Assignment – A Guide for Beginners
- Top 10 Resources to Find Machine Learning Datasets in 2022

