What is a Recommendation System?
Recommendation systems or Recommendation engine in Machine Learning is a way of suggesting similar items and ideas to the user’s interests. Recommender systems are widely used on many applications for recommending products and services to users. The goal of a recommender system is to generate meaningful recommendations to a collection of users for items or products that might interest them. Suggestions of products on Amazon, or movies on Netflix, are real-world examples of the recommender systems.
Recommendation engine in Machine Learning benefits the users in finding items of their interest. It helps item providers in delivering their items to the right user. The recommender system helps to identify products that are most relevant to users. It also helps to provide users with personalized content thus helping companies to improve user engagement.
Role of Recommendation Engine in Machine Learning
Recommendation engine in machine learning systems helps users discover new products and services. Every time users shop online, a recommendation system guides them towards the most likely product they might purchase. Recommender systems are like salespeople who know what you like based on your history and preferences. This system attracts customers with their preferable product and, leads to more sales and increase profit for the company.
Recommendation engines in machine learning serve two major functions, they help users deal with information overload by giving them recommendations of products, and they help businesses make more profits, by selling more products. Recommendation engines in Machine Learning are used by various large name companies like Amazon, Reddit, Google, Instagram, Spotify, Netflix, etc. often to increase engagement with users and the platform.
Examples of Recommendation Engine
There are a variety of applications for recommendations including movies on Netflix, consumer products on Amazon or similar e-commerce sites, music on Spotify, and social media platforms like Instagram, news, and advertising.
The online music player app Spotify would recommend songs similar to the ones you’ve repeatedly listened to or liked so that you can continue using their platform. Amazon uses recommendations to suggest products to various users based on the data they have collected for that user.
Types of Recommendation System
There are 2 types of Recommendation engines in Machine Learning-
1. Collaborative Recommendation System
2. Content-based Recommendation System
1. Collaborative Recommendation System
Collaborative recommendation engines are based on past interactions between users and the target items. Thus, the input to a collaborative system will be all historical data of user interactions with target items. This data is typically stored in a matrix where the rows are the users, and the columns are the items. The core idea behind such systems is that the historical data of the users should be enough to make a prediction. There are two categories of collaborative systems namely memory-based and model-based systems.
Memory-based System
Memory-based systems operate over the entire user-item database to make predictions. These systems employ statistical techniques are employed to find the neighbors of the active user and then combine their preferences to produce a prediction. Once a neighborhood of users is formed, these systems use different algorithms to combine the preferences of neighbors to produce a prediction or top-N recommendation for the active user. The techniques used in this algorithm are also known as nearest-neighbor or user-based collaborative filtering.
Model-based System
In Model-based algorithms, the input is the user data to estimate or learn a model of user ratings. Model-based collaborative algorithms provide item recommendations by first developing a model of user ratings. The model-building process is performed by different machine learning algorithms such as Bayesian network, clustering, and rule-based approaches. This approach applies association rule discovery algorithms to find associations between co-purchased items and then generates item recommendations based on the strength of the association between the items.
Example of Collaborative Recommendation system in Machine Learning
To understand the Collaborative Recommendation system, let’s consider the example of an online food ordering app. When, user A orders two products p1, and p2, and user A orders the same two products p1, p2, and other products p3, then User A will be recommended to buy the product p3. Since the user interest products are similar there is a high chance of User A to buy the product p3.
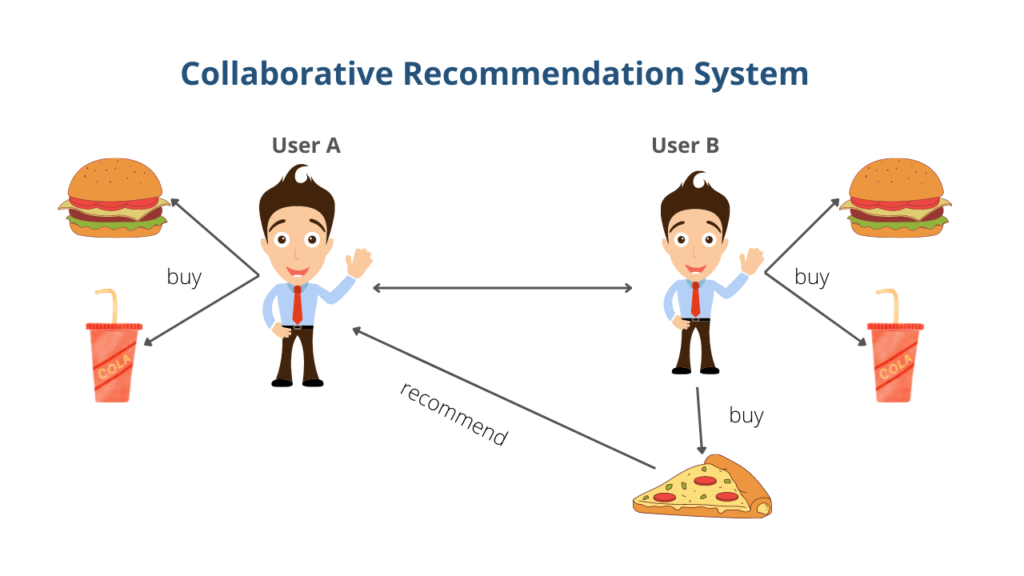
Some other examples of collaborative recommendation systems in machine learning are:
- YouTube content recommendation – recommends videos based on other users who have subscribed or watched similar videos like you.
- Udemy course recommendation – recommends courses based on other individuals who have finished similar courses you have finished.
Advantages of Collaborative systems
- A collaborative filtering application is to recommend interesting or popular information.
- A collaborative filtering system can make a more personalized recommendation by analyzing information from past activity or the history of other users of similar taste.
Disadvantages of Collaborative systems
- Many commercial recommender systems are based on large datasets. As a result, the user-item matrix used for collaborative filtering could be extremely large and sparse, which brings about challenges in the performance of the recommendation.
- As the numbers of users and items grow, traditional collaborative algorithms will suffer seriously
scalability problems. - A collaborative filtering system doesn’t automatically match content to one’s preferences.
2. Content-based Recommendation System
Content-based recommenders refer to such approaches, that provide recommendations by comparing representations of content describing an item to representations of content that interest the user. Content-based recommendation systems try to recommend items similar to those a given user has liked in the past.
In a movie recommendation application, a movie may be represented by such features as specific actors, genre, director, story, etc. The user’s interest or preference is also represented by the same set of features, called the user profile. Recommendations are made by comparing the user profile with items expressed in the same set of features. The top-k best matched or most similar items are recommended to the user.
Example of Content-based Recommendation system in Machine Learning
To understand the Content-based Recommendation system, let’s consider the example of an online book reading site. When the user reads an item i1 and i2, then he will be recommended to read item i3 similar to the previous items. Since the user interest items are similar to the recommendation, there is a high chance of the user reading item i3.

Some other examples of content-based recommendation systems in machine learning are :
- Amazon site – recommend products similar to what you have previously purchased
- Spotify music – recommends songs and podcasts similar to what you have previously listened
Advantages
- The content-based system recommends only the items that interest the user.
- The recommendation is based on the item features, and explicitly lists the features of the content.
- This system helps in recommending new items that are not yet rated by other users
Disadvantages
- In this system, the user will never be recommended for different items, so business cannot be expanded as the user does not try a different type of product.
- This system only recommends those items that score high with the user profile
- For a new user, systems don’t have historical information to recommend items
Comparison of Collaborative and Content-based Recommendation Systems
| Collaborative system | Content-based system |
|---|---|
| Collaborative recommendation systems focus on the relationship between the users and items | Content-Based recommendation systems focus on the properties of items. |
| This system does not work on new items that have no ratings | This system also recommends the new items to users |
| The system does not assume access to side information about items | The system assumes access to side information about items |
| A collaborative system cannot recommend new items | The content-based system can recommend new items |
| Item features are inferred from ratings. | Match the item features with user preferences. |
| Example of Collaborative recommendation system: Netflix movie recommendations | Example for Content-Based recommendation system: Spotify music recommendations |
Steps to build a Recommendation engine in Machine Learning
Let’s see the steps by step process to build a recommendation engine in Machine Learning
Data collection
This is the first and most step in building a recommendation engine. The data can be collected by two means explicitly and implicitly. Explicit data is information that is provided intentionally, and that can be input from the users such as movie ratings. Implicit data is information that is not provided intentionally but gathered from available data streams like search history, clicks, order history, etc.
Data storage
The amount of data tells how good the recommendations of the model can get. For example, in a movie recommendation system, the more rating users give to movies, the better the recommendations get for other users. The type of data plays an important role in deciding the type of storage that has to be used.
Data filtering
After collecting and storing the data, we have to filter it so as to extract the relevant information required to make the final recommendations. There are various algorithms that help us make the filtering process easier.
Measures to evaluate Recommendation engine in Machine Learning
The performance of a recommendation system can be assessed through various tactics which measure coverage and accuracy. The method of evaluation of a recommendation is solely dependent on the dataset and approach used to generate the recommendation. Recommender systems share several conceptual similarities with the classification and regression modeling problem. The common statistical accuracy measures to evaluate the accuracy of a recommender engine are RMSD, MAE, and k-fold cross-validation.
K fold cross validation
Let us consider a model, which will predict how well a user will rate an item based on a set of features. Here, the K fold cross-validation method can be used to infer the results of the model through accuracy metrics. This method is the same as a train test split, except we create many K randomly assigned training and test sets. Each individual training fold is used to train on the recommendation system independently and then measure the accuracy of the resulting systems with the test set. Then, the accuracy score is calculated to know how well the recommendation system is learning. This method is beneficial to prevent your model from overfitting.
MAE(Mean Absolute Error)
Mean Absolute error represents the average absolute value of each error in rating prediction. Lowering the mean absolute error score better the recommendation system.
RMSD(Root Mean Square Deviation)
Root Mean Square Deviation is a similar metric to MAE but has a heavy penalty when the prediction is very far from the true value and a lighter penalty when the prediction is near the true value. It is performed by taking the squares of the difference between true and predicted values instead of the sum of the absolute values. Lower the RMSD score better the recommendation system.
Conclusion
In this article, we have discussed in detail the recommendation engine in machine learning and its types. Recommender systems are one of the most successful and widespread applications of machine learning technologies in business. There is no doubt that more businesses will incorporate recommendation systems in the future.
Thank you for visiting our website.
Also Read:
- Flower classification using CNN
- Music Recommendation System in Machine Learning
- Top 15 Machine Learning Projects in Python with source code
- Gender Recognition by Voice using Python
- Top 15 Python Libraries For Data Science in 2022
- Top 15 Python Libraries For Machine Learning in 2022
- Setup and Run Machine Learning in Visual Studio Code
- Diabetes prediction using Machine Learning
- 15 Deep Learning Projects for Final year
- Machine Learning Scenario-Based Questions
- Customer Behaviour Analysis – Machine Learning and Python
- NxNxN Matrix in Python 3
- 3 V’s of Big data
- Naive Bayes in Machine Learning
- Automate Data Mining With Python
- Support Vector Machine(SVM) in Machine Learning
- Convert ipynb to Python
- Data Science Projects for Final Year
- Multiclass Classification in Machine Learning
- Movie Recommendation System: with Streamlit and Python-ML
- Getting Started with Seaborn: Install, Import, and Usage
- List of Machine Learning Algorithms
- Recommendation engine in Machine Learning
- Machine Learning Projects for Final Year
- ML Systems
- Python Derivative Calculator
- Mathematics for Machine Learning
- Data Science Homework Help – Get The Assistance You Need
- How to Ace Your Machine Learning Assignment – A Guide for Beginners
- Top 10 Resources to Find Machine Learning Datasets in 2022