
In this article on the list of Machine Learning Algorithms, we are going to learn the top 10 Machine Learning Algorithms that are commonly used and are beginner friendly.
We all come across some of the machines in our day-to-day lives as Machine Learning is making our day-to-day life easy from self-driving cars to Amazon virtual assistant “Alexa”. We are all surrounded by humans who can learn everything from their past experiences with their learning capability, and we have computers or machines which work on our instructions. But can a machine also learn from experiences or past data like a human does? So here comes the role of Machine Learning(ML) which plays an important role in our lives.
What is Machine Learning?
Machine Learning (ML) is a type of artificial intelligence (AI) that allows software applications to become more accurate at predicting outcomes without being explicitly programmed to do so.
At its most basic, ML uses programmed algorithms that receive and analyze input data to predict output values within an acceptable range. As new data is fed to these algorithms, they learn and optimize their operations to improve performance, developing ‘intelligence’ over time.
For better understanding let’s look at one of the real-world scenarios like Fraud Detection. Consider, that a company with 10 million users analyzed five percent of all transactions to classify them as fraudulent or not while the rest of the data wasn’t labeled with “fraud” and “non-fraud” tags. In this case, the Machine learning technique allows for running all of the information without having to hire an army of annotators or sacrifice accuracy. Below, we’ll understand all such techniques(algorithms) in deep and how exactly this magic works.
More such examples of Machine Learning are Advertisement Click Classification Case Study, Boston House Price Prediction, Crop Yield Prediction, Face Detection, etc.
Hope you got the answer to the question of what the ML exactly is!
You’ve probably heard of Machine Learning techniques. Let’s see these techniques one by one.
Machine learning algorithms are classified into 4 types:
Supervised Learning:
Supervised Learning is defined by its use of labeled datasets to train algorithms and to classify data or predict outcomes accurately.
In other words, it is learning of the model where with an input variable ( say, x) and an output variable (say, Y) and an algorithm to map the input to the output.
Unsupervised Learning:
Unsupervised Learning is a type of algorithm that learns patterns from untagged data. Learning where only the input data (say, X) is present and no corresponding output variable is present there.
Semi-Supervised Learning:
Semi-supervised machine learning is a combination of supervised and unsupervised machine learning methods. A machine learning technique that uses a small portion of labeled data and lots of unlabeled data to train a predictive model is nothing but semi-supervised learning.
Reinforcement Learning:
Reinforcement learning is the training of machine learning models to make a sequence of decisions. Or in other words, we can say that the output depends on the state of the current input and the next input depends on the output of the previous input.
As we all are now quite familiar with the classification of Machine Learning Learning.
To know more about machine learning systems, check out this article.
However, these four are further classified into more types. Now comes the question, what are those types?
What are the Popular Machine Learning Algorithms?
Below is the list of Top 10 commonly used Machine Learning (ML) Algorithms:
- Linear Regression
- Logistic Regression
- SVM algorithm
- Decision Tree
- Naive Bayes Algorithm
- KNN Algorithm
- K-means Algorithm
- Random forest algorithm
- Dimensionality reduction algorithms
- Gradient boosting and AdaBoosting algorithm
Let’s see all these one by one and try to understand better:
1. Linear Regression
“Linear Regression” is a supervised Learning based algorithm. It attempts to model the relationship between two variables by fitting a linear equation to observed data. One variable is considered to be an explanatory variable, and the other is considered to be a dependent variable. For example, a modeler might want to relate the weights of individuals to their heights using a linear regression model.
Linear regression models are relatively simple and provide an easy-to-interpret mathematical formula that can generate predictions. Linear regression can be applied to various areas in business and academic study.
Representation of Linear Regression Model:
An LR model representation is a linear equation. This line is known as the regression line and is represented by a linear equation Y= a *X + b.
In this equation each term is represented as:
Y – Dependent Variable
a – Slope
X – Independent variable
b – Intercept or bias coefficient

The graph shows the representation of the LR model which is always a straight line. The dimension of the hyperplane of the regression is its complexity.
Data preparation for LR model:
- To transform data for the linear relationship (ex: log transform for exponential relationship)
- For the LR model remove the noise such as outliers
- Should rescale the inputs using standardization or normalization
Advantages of Linear Regression:
- It has a good regression baseline considering the simplicity
- Lasso/Ridge can be used to avoid overfitting and in case of collinearity
Examples of the linear regression model are: Product sales prediction according to prices or promotions.
- Product sales prediction according to prices or promotions.
- Call-center waiting-time prediction according to the number of complaints and the number of working agents.
And this is how Linear Regression in Machine Learning works. Wasn’t that interesting?
2. Logistic Regression:
“Logistic Regression” is the go-to for binary classification algorithm i.e. used for binary classification use cases. Logistic regression focuses on estimating the probability of an event occurring based on the previous data provided. It helps predict the probability(between 0 and 1) of an event by fitting data to a logit function. It is also called logit regression.
Representation of Logistic Regression:
Logistic regression is a linear method but predictions are transformed using the logistic function(or sigmoid). The formula of the sigmoid function is:
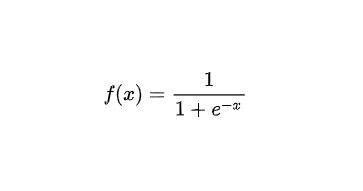
Below is the graph for Logistic Regression:

The sigmoid function forms an S-shaped graph and maps the real-valued numbers in (0,1).
Advantages of Logistic Regression:
- It has a good classification baseline considering the simplicity
- Possibility to change cutoff for precision/recall tradeoff
- The probability output can be used for ranking
Examples of Logistic Regression are:
- Classification of loan defaults according to profile
- Customer scoring with the probability of purchase
Hope you are now aware of how the logistic regression works and its implementation.
3. SVM(Support Vector Machine)
“Support Vector Machine algorithms” are supervised learning models that analyze the data used for classification and regression analysis. It is the algorithm in which you plot raw data as points in an n-dimensional space.
SVM essentially filters data into categories, which is achieved by providing a set of training examples, each set marked as belonging to one or the other of the two categories. The algorithm then works to build a model that assigns new values to one category or the other. The value of each feature is then tied to a particular coordinate, making it easy to classify the data. Lines called classifiers can be used to split the data and plot them on a graph.
Representation of SVM:
In the SVM, a hyperplane is selected to separate the points in the input variable space by their class, with the largest margin. The closest data points (defining the margin) are called the support vectors. But real data cannot be perfectly separated, that is why a C defines the amount of violation of the margin allowed.

The plot shows the representation of SVM. This is how we can use SVMs in classification problems. SVM assumes numeric inputs and may require a dummy transformation of categorical features.
Advantages of SVM:
- It works well in high-dimensional space
- It allows nonlinear separation with nonlinear Kernels
Examples of SVM are:
- Face detection from images
Now, let’s move toward the next algorithm and see how it works?
4. Decision Tree
It is also referred to as CART or Decision Trees, this algorithm is the foundation of Random Forest and Boosted Trees. The decision tree algorithm in machine learning is one of the most popular algorithms in use today. It is a supervised learning algorithm that is used for classification as well as for regression problems.
A decision tree is a flow-chart-like tree structure that uses a branching method to illustrate every possible outcome of a decision. Each node within the tree represents a test on a specific variable and each branch is the outcome of that test.
Representation of Decision Tree:
The model representation is a binary tree, where each node is an input variable m with a split point and each leaf contains an output variable n for prediction.

As, we can see from the diagram the model actually split the input space into (hyper) rectangles, and predictions are made according to the area observations fall into. This is how the algorithm works.
Advantages of Decision Tree Algorithm:
- The algorithm is easy to interpret and has no overfitting with the pruning.
- It works for both regression and classification problems.
- It can take any type of variable without modifications and does not require any kind of data preparation.
Examples of Decision Tree algorithm are:
- Online shopping portal
- Fraudulent transaction classification
5. Naive Bayes Algorithm
The “Naive Bayes classification algorithm” is based on Bayes’ theorem and classifies every value as independent of any other value. It allows us to predict a class/category, based on a given set of features, using probability.
In other words, it selects the best hypothesis h given data d assuming there is no interaction between features.
A Naive Bayesian model is easy to build and is useful for massive datasets. It’s simple and is known to outperform even highly sophisticated classification methods.
Representation of Naive Bayes:
It works on a simple mathematical formula used for calculating conditional probabilities. The formula is:

Advantages of Naive Bayes algorithm:
- It is a good algorithm for a few categories of variables
- It is Fast because of the calculations
- If the naive assumptions work can converge quicker than the other models. It can be used on smaller training data.
Examples of Naive Bayes are:
- Email spam detection is a use case example of this algorithm
- Article classification using binary word presence
6. K-Nearest Neighbors(KNN) Algorithm
KNN stands for “K-Nearest Neighbour”. It is one of the supervised machine learning algorithms. The algorithm can be used to solve both classification and regression problem statements. It stores all the available cases and classifies any new cases by taking a majority vote of its k neighbors.
It is a versatile algorithm also used for imputing missing values and resampling datasets.
Representation of KNN:
KNN uses the entire training set, no training is required to train values. Predictions are made by searching the k similar instances, according to a distance, and summarizing the output.

As we can see from the above diagram with the help of KNN, we can easily identify the category or class of a particular dataset. For regression, the output can be the mean, while for classification the output can be the most common class. Various distances can be used, for example:
Euclidian distance – Euclidean distance is a formula that is used to calculate the distance of K number of neighbors. It is good for a similar types of variables. The euclidian distance formula is:

The best value of k must be found by testing, and the algorithm is sensitive to the Curse of dimensionality.
Advantages of KNN:
- KNN is effective if the training data is large
- It is robust to noisy data, no need to filter outlier
Examples of KNN are:
- Anomaly detection
- Recommending products based on similar customers
These are the use case examples of the KNN algorithm.
7. K-Means Algorithm:
“K-Means Clustering” is an unsupervised learning algorithm that is used to solve clustering problems. Data sets are classified into a particular number of clusters (let’s call that number K) in such a way that all the data points within a cluster are homogenous and heterogeneous from the data in other clusters.
Representation of K-Means:
Step 1: It first selects the number K to decide the number of clusters, these random K points are called centroids.
Step 2: Now, categorize each item to its closest mean and update the mean’s coordinates, which are the averages of all the items categorized in that cluster so far.
Step 3: This process is repeated until the centroids do not change.

Advantages of K-Means:
- Simple clustering approach
- Apply even in case of large data sets
- The algorithm can guarantee the result
Usecase examples of K-Means Clustering:
- Identifying Fake News
- Marketing and Sales
8. Random Forest Algorithm
A “random forest” is a supervised machine learning algorithm that is constructed from decision tree algorithms. It can be used for both Classification and Regression problems in ML.
Random forests or random decision forests are a bigger type of ensemble learning method called as Bootstrap Aggregation or Bagging, combining multiple algorithms to generate better results for classification, regression, and other tasks. Each individual classifier is weak, but when combined with others, can produce excellent results.
The algorithm can handle the data set containing continuous variables as in the case of regression and categorical variables as in the case of classification.
The below diagram illustrates the working of the algorithm:

We can understand the working of the algorithm from the following steps:
Step 1: First, select the random X data points from the training set.
Step 2:Now, with the selected data points (Subsets), build the decision trees.
Step 3: In this step, we will choose the number Y for the decision trees that you want to build. Hence, from every decision tree, we will get the prediction result.
Step 4: After this, for every predicted result voting will be performed. Finally, select the most voted prediction result as the final prediction result.
This is how the Random Forest algorithm works.
Advantages of Random Forest algorithm:
- The random forest produces good predictions that can be understood easily.
- It can handle large datasets efficiently.
Examples of Random Forest algorithm:
- Banking to detect customers who are more likely to repay their debt on time.
- Stock traders use Random Forest to predict a stock’s future behavior.
9. Dimensionality Reduction Algorithms
As we all know a huge amount of data is been generated in the world. As data has become a crucial component of businesses and organizations across all industries, it is essential to process, analyze, and visualize it appropriately to extract meaningful insights(output) from large datasets. However, as a data scientist, you know that this raw data contains a lot of information, and the more amount of data produced every second the more challenging it is to analyze and visualize it to draw valid inferences.
Now, the question arises of how to manage all these tasks?
So, here comes the concept of Dimensionality Reduction.
“Dimensionality Reduction” simply refers to the process of reducing the number of attributes in a dataset while keeping as much of the variation in the original dataset as possible. By applying dimensionality reduction, you can decrease or bring down the number of columns to quantifiable counts, thereby transforming the three-dimensional sphere into a two-dimensional object.
Dimensionality reduction algorithms like Decision Trees, Factor Analysis, Missing Value ratios, and Random Forest can help you find relevant/accurate details.
Advantages of Dimensionality Reduction Algorithm:
- It makes machine learning algorithms computationally efficient.
- It helps in data compression by reducing features.
- It reduces storage.
10. Gradient boosting and AdaBoosting algorithm
“Gradient Boosting” is a machine learning technique used in regression and classification tasks, among others. It gives a prediction model in the form of an ensemble of weak prediction models, which are typically decision trees. AdaBoost was the first successful boosting algorithm developed for binary classification. These boosting algorithms always work well in data science competitions like Kaggle, AV Hackathon, and CrowdAnalytix. These are the most preferred machine learning algorithms today that programmers use.
Representation of algorithm:
Adaboost classifier is of the form given below:

“Adaboosting” is an ensemble learning method, commonly used with decision trees with one level. For the purpose of data, preparation outliers should be removed for AdaBoost.
Advantages of the Algorithm are:
- It is easier to use with less need for tweaking parameters.
- The accuracy of weak classifiers can be improved by using Adaboost.
- It is less prone to overfitting as the input parameters are not jointly optimized.
Came a long way right! I hope you are now pretty clear with all the Popular ML Algorithms it’s working. Try to implement these algorithms in your project code. Also, if you find yourself stuck in your projects “violet-cat-415996.hostingersite.com” always works! You can visit to Trending ML Projects available on our website with the source and code it.
Hope you liked it! Happy Learning!
Thank you for visiting our website.
Also Read:
- Flower classification using CNN
- Music Recommendation System in Machine Learning
- Top 15 Machine Learning Projects in Python with source code
- Gender Recognition by Voice using Python
- Top 15 Python Libraries For Data Science in 2022
- Top 15 Python Libraries For Machine Learning in 2022
- Setup and Run Machine Learning in Visual Studio Code
- Diabetes prediction using Machine Learning
- 15 Deep Learning Projects for Final year
- Machine Learning Scenario-Based Questions
- Customer Behaviour Analysis – Machine Learning and Python
- NxNxN Matrix in Python 3
- 3 V’s of Big data
- Naive Bayes in Machine Learning
- Automate Data Mining With Python
- Support Vector Machine(SVM) in Machine Learning
- Convert ipynb to Python
- Data Science Projects for Final Year
- Multiclass Classification in Machine Learning
- Movie Recommendation System: with Streamlit and Python-ML
- Getting Started with Seaborn: Install, Import, and Usage
- List of Machine Learning Algorithms
- Recommendation engine in Machine Learning
- Machine Learning Projects for Final Year
- ML Systems
- Python Derivative Calculator
- Mathematics for Machine Learning
- Data Science Homework Help – Get The Assistance You Need
- How to Ace Your Machine Learning Assignment – A Guide for Beginners
- Top 10 Resources to Find Machine Learning Datasets in 2022



