Introduction
One of the most challenging tasks is predicting how the stock market will perform. There are so many variables in prediction — physical vs. psychological, rational vs. illogical action, and so on. All of these factors combine to make share prices unpredictable and difficult to anticipate with great accuracy.
Also, the most significant use of Machine Learning in finance is stock market prediction. In this tutorial, we will walk you through a basic Data Science project on Stock Price Prediction using Machine Learning with Python.
By the conclusion of this article, you will understand how to forecast stock prices using the Linear Regression model and the Python programming language.
This post will use historical data from a publicly-traded company’s stock prices. We will use a combination of machine learning algorithms to forecast this company’s future stock price, beginning with simple algorithms like linear regression.
Step 1: Importing required libraries
Let’s look at how to forecast or predict stock prices with Machine Learning and the Python programming language. I’ll begin by importing all of the Python libraries that we’ll require for this task:
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
from sklearn import preprocessing
from sklearn import metrics
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
We need data to get started. This will take the form of historical price information for Tesla Motors (TSLA). This is a direct.csv download from the Kaggle website that I’m importing into memory as a pandas data frame. Download Dataset.
Step 2: Data Preparation And Visualization
data = pd.read_csv("C:/Users/Vatsal Rakholiya/Downloads/TSLA.csv")
data.head()
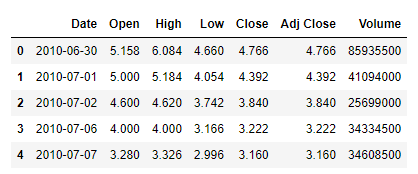
data.info()
data.describe()
Step 3: Splitting Data In X and Y
X = data[['High','Low','Open','Volume']].values
y = data['Close'].values
print(X)

print(y)
Applying Machine Learning Algorithms for stock market prediction
To be effective, machine learning models require at least two types of data: training data and testing data. Given the difficulty of obtaining new data, a frequent method for generating these subsets of data is to divide a single dataset into many groups that we are using for Stock Price Prediction using Machine Learning.
It is typical to use Seventy percent of the data for training and the remaining thirty percent for testing. The most frequent strategy is a 70/30 split, however, other formulaic ways can also be utilized.
Step 4: Test-Train Split
# Split data into testing and training sets
X_train, X_test, y_train, y_test = train_test_split(X,y, test_size=0.3, random_state=1)
We can see that our data has been split into several DataFrame objects, with the nearest whole-number value of rows reflecting our 70/30 split. The test size of 0.30 (30%) was supplied as a parameter to the train test split method.
Step 5: Training the Model
#from sklearn.linear_model import LinearRegression
# Create Regression Model
Model = LinearRegression()
# Train the model
Model.fit(X_train, y_train)
#Printing Coefficient
print(Model.coef_)
# Use model to make predictions
predicted = Model.predict(X_test)
print(predicted)
That’s it; our linear model has been trained, and we’ve obtained predicted values (y pred). Now we can examine our model coefficients as well as statistics such as the mean absolute error (MAE) and coefficient of determination to see how well our model fits our data (r2).
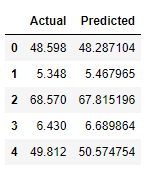
Step 6: Combining The Actual and Predicted data to match
data1 = pd.DataFrame({'Actual': y_test.flatten(), 'Predicted' : predicted.flatten()})
data1.head(20)
Step 7: Validating the Fit
During training, the linear model creates coefficients for each feature and returns these values as an array. In this situation, we have a single characteristic that will be represented by a single value. This is accessible via the model. regr_ attribute.
Furthermore, we can utilize the predicted values from our trained model to calculate the mean squared error and the coefficient of determination using other learn.metrics module functions. Let’s look at a variety of indicators that can be used to assess the utility of our model.
import math
print('Mean Absolute Error:', metrics.mean_absolute_error(y_test,predicted))
print('Mean Squared Error:', metrics.mean_squared_error(y_test,predicted))
print('Root Mean Squared Error:', math.sqrt(metrics.mean_squared_error(y_test,predicted)))
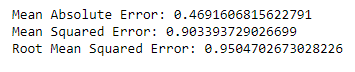
The MAE is the arithmetic mean of our model’s absolute errors, calculated by adding the absolute difference between observed X and Y values and dividing by the total number of observations.
Consider the following chart of our observed values versus expected values to see how this is portrayed visually:
graph = data1.head(20)
graph.plot(kind='bar')

Conclusion
In this tutorial, we learned how to machine learn stock market analysis using python. There are many algorithms for stock market prediction but we have used linear regression for stock price prediction using python. You can use any other algorithms that you may think can be used here. During the analysis of anything using machine learning, there are always some predefined steps here we have used 7 basic steps.
You can learn more about machine learning in our maching learning tutorials.
Thank you for reading this article.
Also Read:
- Download 1000+ Projects, All B.Tech & Programming Notes, Job, Resume & Interview Guide, and More – Get Your Ultimate Programming Bundle!
- Music Recommendation System in Machine Learning
- Create your own ChatGPT with Python
- SQLite | CRUD Operations in Python
- Event Management System Project in Python
- Ticket Booking and Management in Python
- Hostel Management System Project in Python
- Sales Management System Project in Python
- Bank Management System Project in C++
- Python Download File from URL | 4 Methods
- Python Programming Examples | Fundamental Programs in Python
- Spell Checker in Python
- Portfolio Management System in Python
- Stickman Game in Python
- Contact Book project in Python
- Loan Management System Project in Python
- Cab Booking System in Python
- Brick Breaker Game in Python
- 100+ Java Projects for Beginners 2023
- Tank game in Python
- GUI Piano in Python
- Ludo Game in Python
- Rock Paper Scissors Game in Python
- Snake and Ladder Game in Python
- Puzzle Game in Python
- Medical Store Management System Project in Python
- Creating Dino Game in Python
- Tic Tac Toe Game in Python
- Courier Tracking System in HTML CSS and JS
- Test Typing Speed using Python App