Hey, everyone! Today we’re going to work on our first Machine Learning Project and that is “Titanic Survival Prediction”. It’s going to be a really cool project. You’re going to apply all your machine learning skills in this project. Titanic survival prediction is a classification problem where your target is to predict whether the passenger of titanic will survive or not. I hope you’re excited about this project.
So before starting, you need to have lots of things on your system like python, anaconda (jupyter notebook), and many python packages like numpy, pandas, sklearn, etc. But wait, what if I tell you, you don’t need any one of them to make this project. Yes, we are not going to download anything on our system. You just need to sign up on Kaggle. Kaggle is a great platform that holds machine learning competition and provides real-world datasets. It offers a no-setup, customizable, Jupyter Notebooks environment. Now, this article will be more focused on how to think about machine learning projects, rather than just implementation. I suggest you to practice the project in Kaggle itself with me.
Table of Contents
- Understanding the titanic survival prediction project
- Setting up things for any machine learning project.
- Understanding the titanic dataset.
- Importing necessary libraries & loading dataset
- Exploratory Data Analysis
- Data Preprocessing
- Building machine learning model
- Making Predictions
- Submission
Titanic Survival Prediction – Kaggle Challenge
This project is based on the Titanic dataset given on Kaggle. It’s a legendary titanic machine learning competition to kick start your ML journey. Moreover, the competition is simple: use machine learning to create a model that predicts which passengers survived the Titanic shipwreck.
The Titanic Challenge:
The sinking of the Titanic is one of the most infamous shipwrecks in history. On April 15, 1912, the widely considered “unsinkable” Titanic sank after colliding with an iceberg. Unfortunately, there weren’t enough lifeboats for everyone on board, resulting in the death of 1502 out of 2224 passengers and crew.
Goal: Build a predictive model that answers the question: “what sorts of people were more likely to survive?” using passenger data like age, gender, class, etc.
So, we’re going to solve this challenge from scratch and also submit our notebook on Kaggle under this competition. We’re going to cover everything like how to deal with the data, how to analyze data through different plots and graphs, how to do data preprocessing, and finally how to predict things.
First Machine Learning Project
- Firstly, Signup on Kaggle.
- Now, Go to this titanic survival challenge.
- Click on Code & create New Notebook

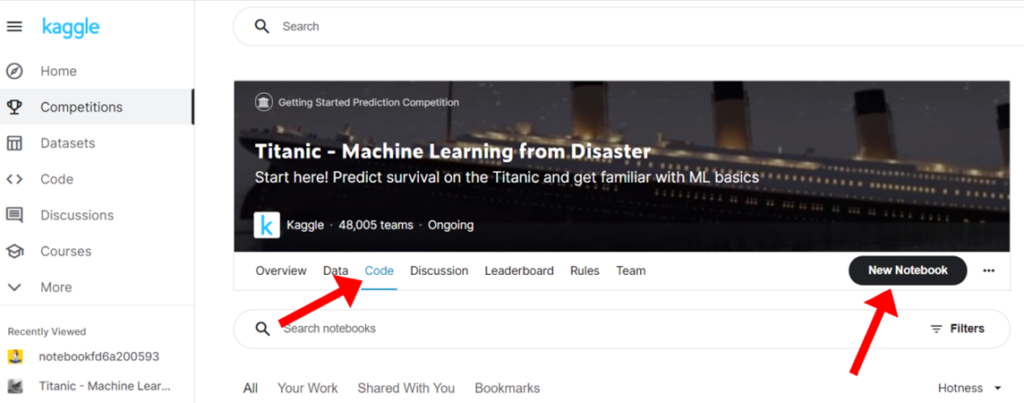
After creating new notebook you’ll see the following screen.

Now this is your notebook where we’re going to make our whole project. Don’t delete the given code. Just press shift + enter to run this cell & to start your session. After this you’ll see this.
/kaggle/input/titanic/train.csv
/kaggle/input/titanic/test.csv
/kaggle/input/titanic/gender_submission.csvCongratulations! You have successfully settled up all the required things.
Understanding the Titanic Dataset
So first we will understand our titanic dataset. This is a dataset of Titanic ship passengers & here
- Each row represents the data of 1 passenger.
- Columns represent the features. We have 10 features/ variables in this dataset.
- Survival: This variable shows whether the person survived or not. This is our target variable & we have to predict its value. It’s a binary variable. 0 means not survived and 1 means survived.
- pclass: The ticket class of passengers. 1st (upper class), 2nd (middle), or 3rd (lower).
- Sex: Gender of passenger
- Age: Age (in years) of a passenger
- sibsp: The no. of siblings/spouses of a particular passenger who were there on the ship.
- parch: The no. of parents/children of a particular passenger who were there on the ship.
- ticket: Ticket Number
- fare: Passenger fare (like 1st class ticket fare must be greater than 2nd pr 3rd class ticket right)
- cabin: Cabin Number
- embarked: Port of Embarkation; From where that passenger took the ship. ( C = Cherbourg, Q = Queenstown, S = Southampton)
Clearly, it’s a classification problem because we need to tell whether the person will survive or not. We will use 5 different classifiers and compare their accuracy. The 5 different classifiers are as follows:
- Random Forest Classifier
- Logistic Regression
- K-Neighbor
- Decision Tree Classifier
- Support Vector Machine
Let the fun begin!
Importing Libraries & Loading Dataset
You’ll see two options in your notebook Code & Markdown. Markdown are for creating bookmarks/notes. Code is for actual coding.
Click on markdown & write the following line. Press shift + enter.
# **1. Importing Necessary Libraries**Now we’re going to need the following libraries:
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.neighbors import KNeighborsClassifier
from sklearn import tree,svm
from sklearn.metrics import accuracy_scoreAfter this, we need to load our dataset to start working. To load our dataset we’ll use the read_csv method of pandas library. Observe the first 10 rows of the dataset. (Press Shift + enter to run the cell)
train_data = pd.read_csv('/kaggle/input/titanic/train.csv')
# Printing first 10 rows of the dataset
train_data.head(10)
print('The shape of our training set: %s passengers and %s features'%(train_data.shape[0],train_data.shape[1]))train_data.info()<class 'pandas.core.frame.DataFrame'>
RangeIndex: 891 entries, 0 to 890
Data columns (total 12 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 PassengerId 891 non-null int64
1 Survived 891 non-null int64
2 Pclass 891 non-null int64
3 Name 891 non-null object
4 Sex 891 non-null object
5 Age 714 non-null float64
6 SibSp 891 non-null int64
7 Parch 891 non-null int64
8 Ticket 891 non-null object
9 Fare 891 non-null float64
10 Cabin 204 non-null object
11 Embarked 889 non-null object
dtypes: float64(2), int64(5), object(5)
memory usage: 83.7+ KBAs you can see we have 891 entries in total but some of the columns have less than 891 entries so that means we have missing values in these columns namely Age, Cabin & Embarked. So we have to preprocess our data first before training our ml model.
# Checking Null Values
train_data.isnull().sum()PassengerId 0
Survived 0
Pclass 0
Name 0
Sex 0
Age 177
SibSp 0
Parch 0
Ticket 0
Fare 0
Cabin 687
Embarked 2
dtype: int64There are 177 missing entries in Age column. 687 missing entries are in Cabin column and 2 missing are in Embarked.
Exploratory Data Analysis
Now we will analyze our data to see which variables are actually important to predict the value of the target variable. Hence, we are going to plot a heat map to see the correlation between the parameters and the target variable (Survived).
heatmap = sns.heatmap(train_data[["Survived", "SibSp", "Parch", "Age", "Fare"]].corr(), annot = True)
sns.set(rc={'figure.figsize':(12,10)})
Now see the decimal values in the above color 2D matrix. These values are the correlation values. Just compare the survived column with the rest of the columns. The lighter the color is the more correlated the value is. Let’s compare the Survived with Sibsp you’re getting the value -0.035. It means that SibSp is not correlated to Survived. Then Parch has a 0.082 value which shows very little correlation. Then Age, again no correlation. In the end, we have Fare whose value of correlation with the Survived variable is 0.26 which shows that the more the fare is, the more are the chances of survival.
Conclusion: But it does not mean that the other features are useless. We’ll explore more about them later.
Moving on, now we will understand all the features one by one. We’ll visualize the impact of each feature on the target variable. Let us start with SibSp that is the no. of siblings or spouses a passenger has.
SibSp – Number of Siblings / Spouses aboard the Titanic
To visualize surviving probability with respect to SibSp we will plot a bar graph.
# Finding unique values
train_data['SibSp'].unique()bargraph_sibsp = sns.catplot(x = "SibSp", y = "Survived", data = train_data, kind="bar", height = 8)
Conclusion:
- Passengers having 1 or 2 siblings have good chances of survival
- More no. of siblings -> Fewer chances of survival
Age Column
We’ll plot a graph so as to see the distribution of age with respect to target variable.
ageplot = sns.FacetGrid(train_data, col="Survived", height = 7)
ageplot = ageplot.map(sns.distplot, "Age")
ageplot = ageplot.set_ylabels("Survival Probability")
Conclusion More age -> less chances of survival!
Gender Column
For gender we are simply going to use seaborn and will plot a bar graph.
sexplot = sns.barplot(x="Sex", y="Survived", data=train_data)
You can see from the above graph it’s quite obvious to say that man has less chances of survival over females. (Remember the Titanic scene when everyone was saying “Women and children first!” I want you to comment down “YES!” if you remember this scene.)
Pclass Column
Let us now see whether the class plays any role in survival probability or not.
pclassplot = sns.catplot(x = "Pclass", y="Survived", data = train_data, kind="bar", height = 6)

So a first class passenger has more chances of survival over 2nd and 3rd class passengers & Similarly the 2nd class passengers have more chances of survival over 3rd class passengers.
That’s all about data exploratory analysis. Now we have a good idea about our data. And one more thing to notice here is there are some features which have nothing to do with survival probability like PassengerId, Ticket number, Cabin number and also the name of the passenger. So we can safely drop them before building our ml model. Moreover, we also need to handle missing values. So, all of these tasks come under Data Preprocessing.
We’re going to cover further topics in the next part till then keep learning & keep coding! Make sure you drop a comment “Nice article!” if you like this article.
Here’s the complete code we’ve discussed so far in this article: Kaggle Notebook.
Try these articles for machine learning basics:-
- Machine Learning: A Gentle IntroductionIntroduction to Machine Learning Machine Learning is probably one of the most interesting and hyped branches of computer science. The thing that separates humans from machines is the fact that humans learn from their experiences. But is it possible to make a machine learn? And The answer is Yes! It is possible through Machine Learning….
- Machine Learning Course DescriptionBefore you start, let me give you an overview of what this series has to offer you. Our machine learning course series comprises of the following sections:- ML Environment Setup and Overview Jupyter Notebook: The Ultimate Guide Numpy Pandas Matplotlib Seaborn Sklearn Linear Regression Logistic Regression Decision Tree Random Forest Support Vector Machine K Nearest…
- ML Environment Setup and OverviewIntroduction to Machine Learning In this article, you will learn about the ML Environment Setup, Machine Learning terminology, its paradigms, and a tutorial to help you set up your machine so you can code what you learn. Before we start with our ML Environment Setup, read this article to get an overview of machine learning….
- Jupyter Notebook: The Ultimate GuideIntroduction to Jupyter Notebook Whenever one starts programming the first aim of that person is to find an IDE that suits his/her needs. In ML there are times when you’ll want to keep a check on your data after doing a change. But in code editors like Vim, Vscode, etc. you have to run your…
- Numpy For Machine Learning: A Complete GuideUp until now you’ve learned about the general idea of what ML does, set up your environment, and got to know about the working of your coding environment i.e. Jupyter Notebook. In this section, you’ll learn about a very powerful library called Numpy. We’ll learn about Numpy Array(np array for short) and operations on them,…
- Python Pandas Tutorial: A Complete Introduction for BeginnersIn the previous section, we learned about Numpy and how we can use it to load, save, and pre-process data easily by using Numpy Arrays. Now Numpy is a great library to do data preprocessing but I’d like to tell you all about another wonderful Python library called Pandas. At the end of this tutorial,…
- Matplotlib Python: A Beginner’s WalkthroughWe know how to analyze data by analyzing the statistics of the data and we’ve learned how to manipulate the data. But is statistics enough to analyze the data? Short answer, Visualization of data is necessary in order to find details that we missed that’s why Matplotlib Python is the best library to visualize data…
- Seaborn: Create Elegant PlotsIn the previous tutorial, we learned why data visualization is important and how we can create plots using matplotlib. In this tutorial, we’ll learn about another data visualization library called Seaborn, which is built on top of matplotlib. But why do we need seaborn if we have matplotlib? Using seaborn you can make plots that…
- Set up Python EnvironmentNow, it’s time to install the tools that we will use to write programs. So, we will be learning to Set up Python Environment in this article. Let’s start. 1. Installing Python first. First, we need to go to the official site of python: https://www.python.org/ Now we need to go to the downloads page of…
- Linear Regression: Your 1st Step in Machine LearningHi guys! So until now, we’ve learned about how we can use libraries to play with data. We did data analysis on a real dataset and we also learned how to visualize data. But what was the purpose behind it? Why do so many things? What are we trying to achieve? I’ll tell you all…