
Introduction
A company runs successfully due to its customers. Understanding the need of customers and fulfilling them through the products is the aim of the company.
Most successful businesses achieved the heights by knowing the need of customers and dynamically changing their strategies and development process.
Customer Behaviour Analysis is as important as a customer for a company or firm. It is a qualitative and quantitative observation of how customers interact with the company. It is important to ensure customers’ needs and desires, contributing to customer loyalty and retention.
What is Customer Analysis?
According to medium.com, Customer analytics is critical for gaining a thorough understanding of customers’ purchasing habits, use trends, demographic distribution, and profitability. Organizations must devote a significant amount of time and resources to learning about their consumers and analyzing the data created by their interactions with them.
How customer behavior analysis can be carried out?
On a small scale or where the data is very less, this can be done manually by understanding the data.
Wherein, cases, where the customer’s dataset is huge and it is almost impossible to look for individual rows manually and find some patterns from data, Machine Learning comes to the rescue!
There are several built-in algorithms and models available in Machine Learning, making the analysis procedure at peak of easy.
There are various frameworks designed and used by data scientists to carry out this analysis. One of the frameworks is,
STP
STP stands for Segmentation, Targeting, and Positioning. It is a three-step marketing framework. With the STP process, it is easy to segment the market, target the customers, and position the offering to each segment.

Segmentation:
Segmentation is the process of dividing a population, potential or existing customers into groups with shared similar characteristics. This group will have comparable purchase behaviors. This Segment will likely respond to different marketing activities.
Targeting:
Targeting deals with the evaluation of potential profits from segments and deciding which segments to focus on. Considering factors to determine where to extend to the whole segment or part of the segment.
Positioning:
After deciding where to Target, positioning is next. Positioning in marketing is a strategic process that entails developing an identity of a brand or product in the mind of potential buyers.
Customer segmentation with the STP framework can be carried out using PCA, Hierarchical Clustering, and K-Means Algorithm in Python using supported libraries like Numpy, Matplotlib, Seaborn, StandardScaler, Scipy, etc.
RFM
RFM segmentation enables marketers to target specific groups of consumers with communications that are far more relevant to their individual behaviors. This practice results in much greater response rates and improved loyalty and customer lifetime value.
RFM segmentation is an effective tool to identify groups of consumers who should be treated differently. RFM stands for Recency, Frequency, and Monetary.
The advantage of RFM over other segmentation models is that it employs objective numerical scales to produce a high-level picture of consumers that is both succinct and instructive. Also, marketers can utilize it without expensive tools. And the most important factor, the segmentation method’s output is simple to comprehend and analyze.
Clustering
Clustering is the unsupervised learning method. It is a technique where a group of data is partitioned into different clusters. There are many popular algorithms for clustering like the K-means algorithm, Mean Shift, BIRCH, OPTICS, Special Clustering, etc. Each algorithm offers a different approach to the challenge of discovering natural groups in data.
All the clusters are significantly different from each other while all the data elements inside the same clusters are of the same category. Distance-based clustering groups the points into some number of clusters such that distances within the cluster should be small while distances between clusters should be large.
One of the most powerful and popular algorithms in Python, the K-means Clustering algorithm can be used to categorize data into clusters.
For eg., if you want to target any particular type of customer for a new product, you can cluster the data into the corresponding categories and really try to find the patterns in between them. And then analyzing the output of various algorithms or PCA to come to a solution.
Logistic Regression
Logistic Regression is a linear classifier, which predicts the outcome as a categorical value. Maybe True or False, 1 or 0, Human or Animal, etc. kinds of binary outcomes are predicted by logistic regression.
On the basis of logistic regression, we can predict if the customer can have an interest in a particular product.
For eg, here, we are going to understand in little depth by taking a problem statement and then generating the outcome related to customer behavior analysis.
Problem Statement:
A company wants to find out whether their old or new customer is interested in buying a car. We have to predict the possibility from the dataset given.
The dataset:
You can download the dataset from here: https://www.kaggle.com/datasets/rakeshrau/social-network-ads
In the dataset, we have UserID, Gender, Age, Salary, and a binary variable Purchased. Out of all these, UserID, Gender, Age and Salary are independent variables whereas if the customer has purchased the product is the dependent term.
Approach:
The marketing team can target only those customers who have the possibility to buy the products.
Hence, we will predict 0 or 1 as outcomes representing whether the customer will buy a car or not.
Let’s begin:
Import the libraries:
To preprocess data we’ll need,
import numpy as np
import matplotlib.pyplot as plt
import pandas as pdImport the dataset:
We need age and estimated salary as our independent variables, so we’ll only consider them as X.
Y would be the dependent variable ‘Purchased’ which has to be predicted
dataset = pd.read_csv('Social_Network_Ads.csv')
X = dataset.iloc[:, 2:4].values
y = dataset.iloc[:, -1].valuesSplit the dataset into train and test:
We will use scikit learns train_test_split method to split our dataset into training and testing.
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.25, random_state = 0)We can check the data,
print(X_train)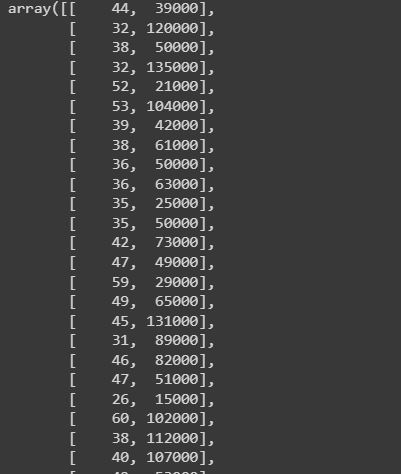
We can see large rows of train data.
Similarly, we can check X_test, y_train, and y_test.

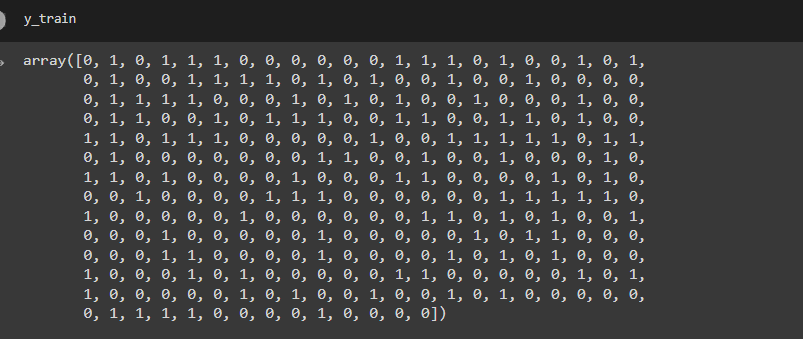
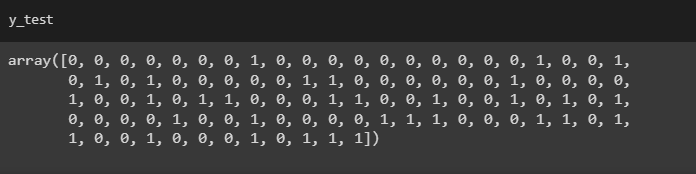
Feature Scaling:
What is feature scaling?
Feature Scaling is a data pre-processing step and applied to independent variables or features of the data. It basically helps to normalize the data within a particular range. Sometimes, it also helps in speeding up the calculations in an algorithm.
Here, it is not required but improving training performance is necessary.
from sklearn.preprocessing import StandardScaler
sc = StandardScaler()
X_train = sc.fit_transform(X_train)
X_test = sc.transform(X_test)Here, we are normalizing the train and test data.
X_train
X_test
Build Model with Logistic Regression:
When comes to Python, has all the powerful models built in, hence is no need to create anything from scratch. Just import the module and fit the data into it to train the model.
from sklearn.linear_model import LogisticRegression
classifier = LogisticRegression(random_state = 0)
classifier.fit(X_train, y_train)Test result prediction:
Let’s predict the result for the test data.
We are comparing this prediction with our y_train i.e. original result to see how our model is doing.
y_pred = classifier.predict(X_test)
print(np.concatenate((y_pred.reshape(len(y_pred),1),y_test.reshape(len(y_test),1)),1))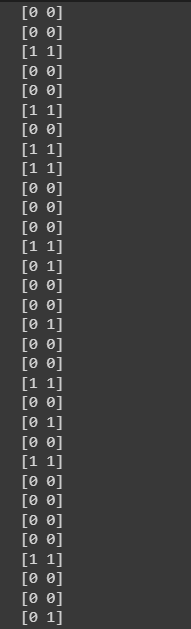
Hmm, it is quite well. But how well?
Accuracy score with Confusion Matrix:
We’ll use the confusion matrix utility to calculate the accuracy of this model.
from sklearn.metrics import confusion_matrix, accuracy_score
cm = confusion_matrix(y_test, y_pred)
print(cm)
Here, for test data, 65 is the correct prediction for class 0 i.e. not buy and 3 is incorrect for class 1 i.e. buy, and in training 8 is incorrect for class 0 and 24 is correct for class 1.
Let’s calculate the accuracy score:
accuracy_score(y_test, y_pred)#Output
0.89Hurray! Our model is 89% true.
Predict for new data:
Let’s take the input value and depict what our model predicts:
Predicting new results:
age=int(input("Enter the age: "))
salary = int(input("Enter the estimated salary: "))
result = classifier.predict(sc.transform([[age,salary]]))
print(result)
Let’s make the result more readable:
if result==[1]:
print("Yay! This customer can buy a car!")
else:
print("Sorry! It seems this customer won't buy a car")Let’s print the result again for the previous inputs.

Let’s run for one more,

Seems great!
For more detailed info, you can check https://www.ris-ai.com/predicting-customer-behavior-with-logistic-regression
This is how we can really use ML integrated with Python and build such analysis to set the target and retain the customers.
Thank you for visiting, don’t forget to check violet-cat-415996.hostingersite.com
Also Read:
- Flower classification using CNN
- Music Recommendation System in Machine Learning
- Top 15 Machine Learning Projects in Python with source code
- Gender Recognition by Voice using Python
- Top 15 Python Libraries For Data Science in 2022
- Top 15 Python Libraries For Machine Learning in 2022
- Setup and Run Machine Learning in Visual Studio Code
- Diabetes prediction using Machine Learning
- 15 Deep Learning Projects for Final year
- Machine Learning Scenario-Based Questions
- Customer Behaviour Analysis – Machine Learning and Python
- NxNxN Matrix in Python 3
- 3 V’s of Big data
- Naive Bayes in Machine Learning
- Automate Data Mining With Python
- Support Vector Machine(SVM) in Machine Learning
- Convert ipynb to Python
- Data Science Projects for Final Year
- Multiclass Classification in Machine Learning
- Movie Recommendation System: with Streamlit and Python-ML
- Getting Started with Seaborn: Install, Import, and Usage
- List of Machine Learning Algorithms
- Recommendation engine in Machine Learning
- Machine Learning Projects for Final Year
- ML Systems
- Python Derivative Calculator
- Mathematics for Machine Learning
- Data Science Homework Help – Get The Assistance You Need
- How to Ace Your Machine Learning Assignment – A Guide for Beginners
- Top 10 Resources to Find Machine Learning Datasets in 2022



