
Introduction
As a developer, you may need to Extract Text From Images. We can write a Python program to extract such textual information from each and every image. In Python, we can use the Pytesseract package for this OCR(Optical Character Recognition) process.
Adding Libraries
To get started with the Python script, we need to install a few required libraries.
Pytesseract
To install pytesseract, run the following command:
pip install pytesseractPillow
Pillow library acts as an image interpreter with all image processing capabilities.
To install the pillow, run the following command:
pip install pillowOpencv-python
We will use OpenCV to recognize texts from the media files (images).
To install OpenCV-python, run the following command:
pip install opencv-pythonCreating a Python tesseract script to Read Text From Images
Importing Libraries
We’re almost ready to read text from images. Before that, though, you need to import the Pytesseract, Pillow, OpenCV, and Numpy libraries for extracting text from image python
# Import libraries
from PIL import Image
import pytesseract
import cv2
import numpy as np
from pytesseract import Output
import osThe following script specifies the path for the Tesseract engine executable file we installed earlier. If you installed Tesseract OCR in a different location, you need to update your path accordingly.
pytesseract.pytesseract.tesseract_cmd = r'C:/Program Files/Tesseract-OCR/tesseract.exe'Extract text from images
# Simply extracting text from image
image = Image.open("A:/Freelance/Projects/demo.jpg")
image = image.resize((300,150))
custom_config = r'-l eng --oem 3 --psm 6'
text = pytesseract.image_to_string(image,config=custom_config)
print(text)The first step in reading text from an image is to open the image. You can do so by using the open() method of the Pillow library’s Image object. To read the text from an image, first, pass the image object you just opened to the Pytesseract module’s image to string() method. This is a pytesseract image to string article. The image to string() method converts the image text into a Python string, which you can then use however you like. Using the print() method, we’ll simply print the string to our screen. To read the text from the car license plate image, run the script below.
Note: You’ll need to update the path of the image to match the location of the image you want to convert to string.
custom_config = r'-l eng --oem 3 --psm 6'Here in the custom configuration you can see the “eng” which indicates the English language i.e it will recognize the English letters you can also add multiple languages and “PSM” means Page segmentation which set the configuration of how the chunks will recognize the characters and “OEM” is the default configuration.
filename = "A:/demo.txt"
os.makedirs(os.path.dirname(filename), exist_ok=True)
with open(filename, "w") as f:
f.write(text)And to save that text, we create a file called demo. Every word from our image is saved in this file, so we can use it elsewhere in extracting text from image python.
Now, let’s test our code with the image below as input.

Complete code for extracting text from image python
# Import libraries
from PIL import Image
import pytesseract
import cv2
import numpy as np
from pytesseract import Output
import os
#Specifies PATH of Tesseract
pytesseract.pytesseract.tesseract_cmd = r'C:/Program Files/Tesseract-OCR/tesseract.exe'
# Simply extracting text from image
image = Image.open("A:/Freelance/Projects/demo.jpg")
image = image.resize((300,150))
custom_config = r'-l eng --oem 3 --psm 6'
text = pytesseract.image_to_string(image,config=custom_config)
print(text)
#To Save The Text in Text file
filename = "A:/demo.txt"
os.makedirs(os.path.dirname(filename), exist_ok=True)
with open(filename, "w") as f:
f.write(text)
Output:

The output below shows that the characters from the Passage have been correctly read. However, in addition, ♀ this symbol is also printed in the output.
The output shows that though Tesseract OCR can read text from an image, it is not 100% correct. An accuracy rate of less than 100% is typical with all OCR engines, so don’t let this discourage you.
You can search this(OpenCV put text) on google to know how python’s OpenCV library can convert images to text
Setting up Tesseract
OCR (Optical Character Recognition) is a technique that recognizes or Extracts Text From Images. It may be used to transform handwritten or printed texts that are difficult to read into machine-readable.
You must install and set up tesseract on your PC before you can use OCR.
Install and Run Tesseract for Windows in 4 Easy Steps
Step-1. First, download the Tesseract OCR executables here.
- Once you open the executable file, you’ll have to first select a language.

Click the “Next” button on the following dialog box.
Step-2. Configure Installation
- Installer Language
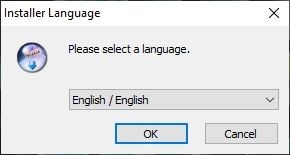
Click the “ok” button on the following dialog box.
- License Agreement

You’ll be presented with a license agreement, as shown below. Click the “I Agree” button if you agree to the terms.
- Tesseract OCR Setup





Step-3. Add Tesseract OCR for Windows Installation Directory to Environment Variables

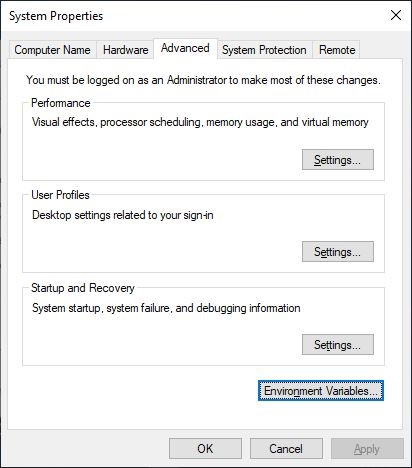
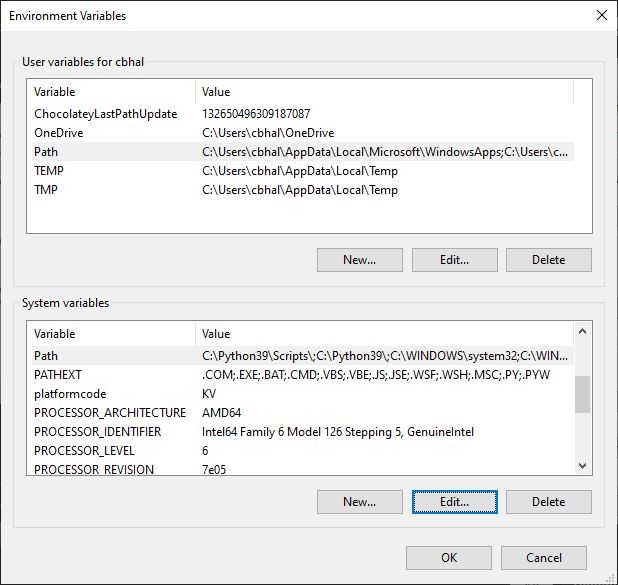

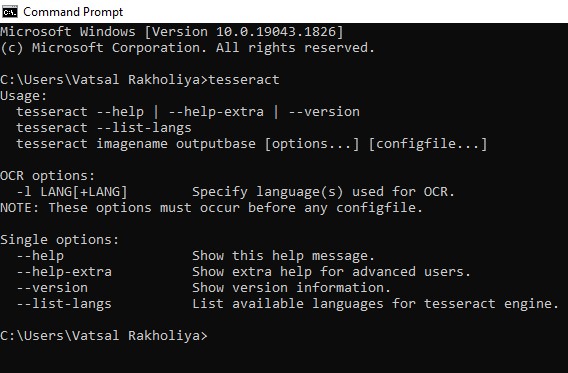
Step-4. After the operation is completed, use the tesseract -v command to ensure that the OCR is installed
Conclusion
We began by learning how to install tesseract, a text extraction program. Then we grabbed a picture and retrieved the text from it and stored it in a text file. We discovered that in order to extract text from complicated pictures, we must employ OpenCV’s image modification methods. I hope you enjoyed this tutorial and found it helpful.
Thank you for reading this article, click here to start learning Python in 2022.
Also Read:
- Download 1000+ Projects, All B.Tech & Programming Notes, Job, Resume & Interview Guide, and More – Get Your Ultimate Programming Bundle!
- Music Recommendation System in Machine Learning
- Create your own ChatGPT with Python
- SQLite | CRUD Operations in Python
- Event Management System Project in Python
- Ticket Booking and Management in Python
- Hostel Management System Project in Python
- Sales Management System Project in Python
- Bank Management System Project in C++
- Python Download File from URL | 4 Methods
- Python Programming Examples | Fundamental Programs in Python
- Spell Checker in Python
- Portfolio Management System in Python
- Stickman Game in Python
- Contact Book project in Python
- Loan Management System Project in Python
- Cab Booking System in Python
- Brick Breaker Game in Python
- 100+ Java Projects for Beginners 2023
- Tank game in Python
- GUI Piano in Python
- Ludo Game in Python
- Rock Paper Scissors Game in Python
- Snake and Ladder Game in Python
- Puzzle Game in Python
- Medical Store Management System Project in Python
- Creating Dino Game in Python
- Tic Tac Toe Game in Python
- Courier Tracking System in HTML CSS and JS
- Test Typing Speed using Python App



