
Description of DataSet
We have selected the dataset that has data related to pokemon. Our data set has meaningful columns. We have 721 rows and 23 columns. In our dataset, we have considered the isLegendary column as a base column in each of our machine learning models. This is a binary column that has only categorical data in it for the Pokemon Analysis Project in ML and Data Science using Python
Below is the description of dataset columns:
- Type_1: Primary type of Pokémon. It is related the nature, with its lifestyle and with the movements it is able to learn for the fighting time. This categorical value can take 18 different values: Bug, Dark, Dragon, Electric, Fairy, Fighting, Fire, Flying, Ghost, Grass, Ground, Ice, Normal, Poison, Psychic, Rock, Steel, and Water.
- Type_2: Pokémon can have two types, but not all of them do. The possible values this second type can take are the same as the variable Type_1.
- Total: The sum of all the base battle stats of a Pokémon. It should be a good indicator of the overall strength of a Pokémon. It is the sum of the next six variables. Each of them represents a base battle stat. All the battle stats are continuous yet integer variables, i.e. the number of values they can take is infinite in theory, or just very big in the practice.
- HP: Base health points of the Pokémon. The bigger it is, the longer the Pokémon will be able to stay in a fight before they faint and leave the combat.
- Attack: Base attack of the Pokémon. The bigger it is, the more damage its physical attacks will deal to the enemy Pokémon.
- Defense: Base defense of the Pokémon. The bigger it is, the less damage it will receive when being hit by a physical attack.
- Sp_Atk: Base special attack of the Pokémon. The bigger it is, the more damage its special attacks will deal with the enemy Pokémon.
- Sp_Def: Base special defense of the Pokémon. The bigger it is, the less damage it will receive when being hit by a special attack.
- Speed: Base speed of the Pokémon. The bigger it is, the more times the Pokémon will be able to attack the enemy.
- Generation. The generation where Pokémon was released. It is an integer between 1 and 6, so it is a numerical discrete variable. It could let us analyze the development or the growth of the game through the years.
- isLegendary: Boolean indicating whether the Pokémon is legendary or not. Legendary Pokémon tend to be stronger, have unique abilities, be really hard to find, and be even harder to catch.
- Color: Color of the Pokémon according to the Pokédex. The Pokédex distinguishes between ten colors: Black, Blue, Brown, Green, Grey, Pink, Purple, Red, White, and Yellow.
- hasGender: Boolean indicating the Pokémon can be classified as male or female.
- Pr_Male: In case the Pokémon has Gender, the probability of its being male. The probability of being female is, of course, 1 minus this value.
- Egg_Group_1: Categorical value indicating the egg group of the Pokémon. It is related to the race of the Pokémon.
- Egg_Group_2: Similarly to the case of the Pokémon types, Pokémon can belong to two egg groups.
- hasMegaEvolution: Boolean indicating whether a Pokémon can mega-evolve or not. Mega-evolving is the property that some Pokémon have and allows them to change their appearance, types, and stats during combat into a much stronger form.
- Height_m: Height of the Pokémon according to the Pokédex, measured in meters. It is a numerical continuous variable.
- Weight_kg: Weight of the Pokémon according to the Pokédex, measured in kilograms. It is also a numerical continuous variable.
- Catch_Rate: Numerical variable indicating how easy is to catch a Pokémon when trying to capture it to make it part of your team. It is bounded between 3 and 255.
- Body_Style: Body style of the Pokémon according to the Pokédex. 14 categories of body style are specified: bipedal_tailed, bipedal_tailless, four_wings, head_arms, head_base, head_legs, head_only, insectoid, multiple_bodies, quadruped, serpentine_body, several_limbs, two_wings, and with_fins.
CODES for Pokemon Analysis Project in ML and Data Science using Python
EDA

In the above cell, we are importing the libraries. We have imported seaborn, matplotlib, numpy, and pandas.
We have used pd. read excel ( ) function to read the excel dataset.

We are using shape ( ) function to print the number of rows and columns in the dataset.

Next, we are using the dtypes ( ) function to print the data type of each column. The screenshot is attached below

Afterward, we have used the isnull( ) function followed by sum( ) to find the number of null values in each column.
This is a data science and ml project of Pokemon Analysis using Python for final year students
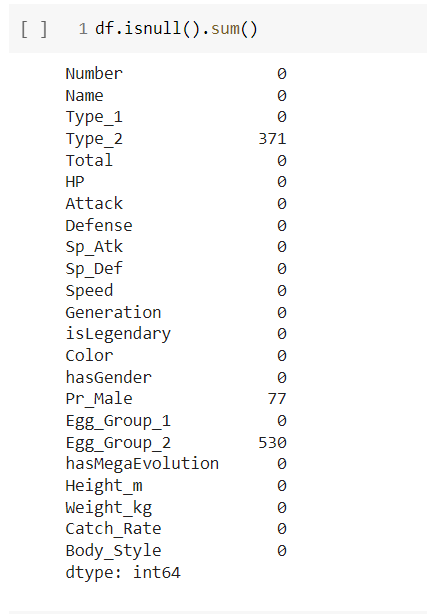
We have used describe ( ) function to print the basic statistical values of all data columns that are numeric
Data Visualization

In the above screenshot, we have plotted a heat map using the seaborn library for df.corr ( ).
Afterward, we started plotting the box plots for all the numeric columns present in our
dataset.
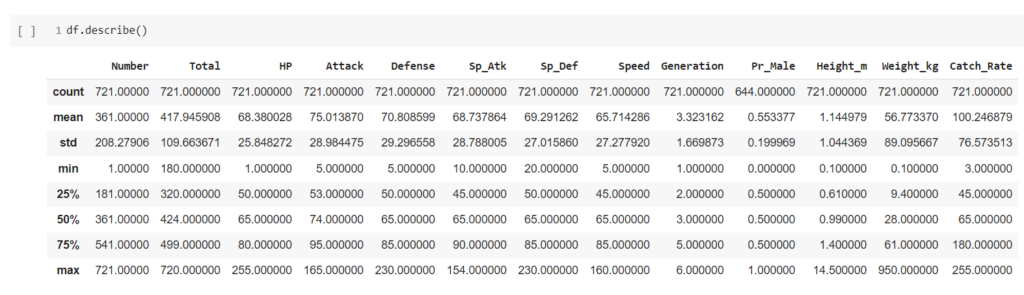
Firstly, we have plotted the box plot for the ‘HP’ column of our dataset.
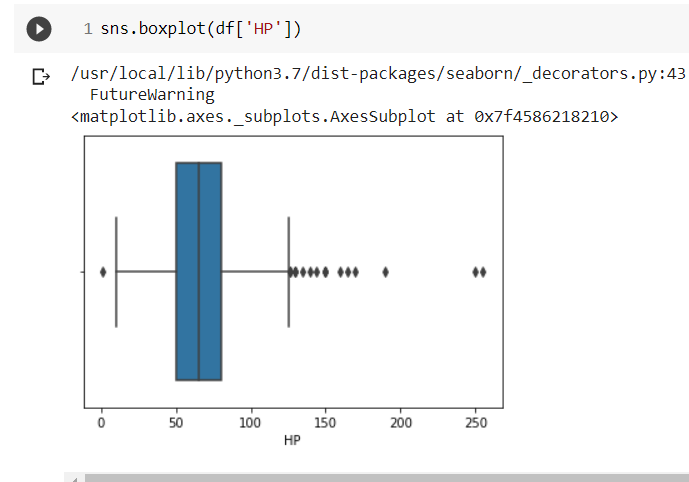
Next, we have plotted the box plot for the ‘ATTACK’ column of our dataset.
Next, we have plotted the box plot for the ‘Defense’ column of our dataset.

Next, we have plotted the box plot for the ‘Sp Atk’ column of our dataset.
This is an AI and ML project of Pokemon Analysis Project with Python for final year project

Next, we have plotted the box plot for the ‘Sp Def’ column of our dataset.

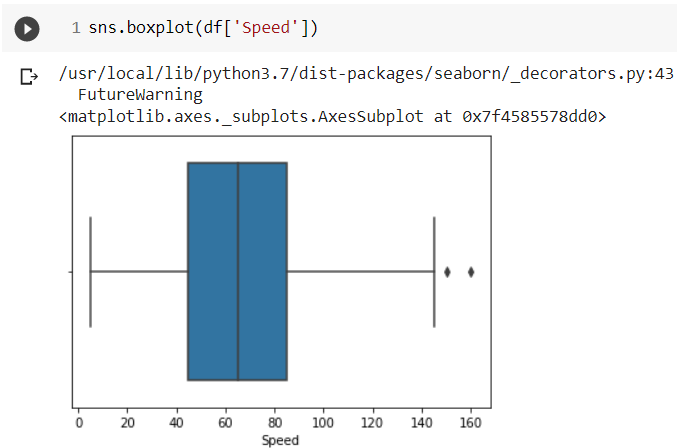
Next, we have plotted the box plot for the ‘Speed’ column of our dataset
Next, we have plotted the box plot for the ‘Generation’ column of our dataset.

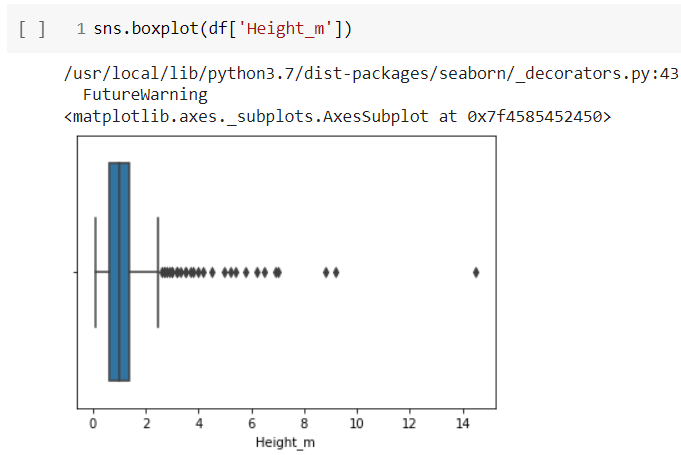
Next, we have plotted the box plot for the ‘Height m’ column of our dataset.
Here, you can check that this project is an assignment for usually final year students related to deep learning, ML, Data Science, AI, etc. We also do every kind of project related to programming, web development, mobile apps, AI, ML, and Data Science. Just contact this number on WhatsApp to know more–> +91-9760648231
Next, we have plotted the box plot for the ‘Weight kg’ column of our dataset.

Next, we have plotted the box plot for the ‘Catch Rate’ column of our dataset. We can see that
many outliers are present in the column values.

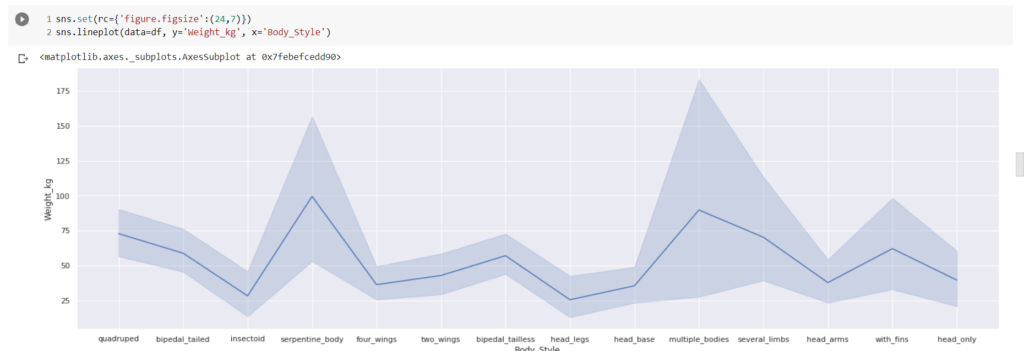
We have generated a line graph for body styles. We have plotted their weights on the line graph
We have also presented the count of pokemon for each body style. We have differentiated them based on their gender.

Lastly, we have plotted the number of legendary and non-legendary pokemon.

Machine Learning part for Pokemon Analysis Project in ML and Data Science using Python
Firstly, we need to prepare the dataset for training and testing the models.
We are dropping irrelevant columns for that

Then, we are printing the information of resultant (relevant) dataframe columns

Model 1: RANDOM FOREST CLASSIFIER
We are first, importing the sklearn libraries required for the random forest classifier

Then, we are considering the isLegendary column of the dataframe because of its categorical nature. We have dropped the isLegendary column from the dataset and stored it in the X variable. The value of the isLegendary column is stored in the Y variable.
We have used train_test_split ( ) to split the data into a 20: 80 ratio.

We have obtained an accuracy score of 99.31 % and a ROC AUC score of 0.996. We can say that our model is pretty much accurate to use.

We have used a classification report from sklearn metrics. We have generated the confusion matrix for the random forest model.

Model 2: DECISION TREE CLASSIFIER
We are first, importing the sklearn libraries required for the decision tree classifier.

We have stored the decision tree classifier in the ‘MODEL’ variable.

Then, we are considering the isLegendary column of the dataframe because of its categorical
nature. We have dropped the isLegendary column from the dataset and stored it in the X variable. The value of the isLegendary column is stored in the Y variable.
We have used train_test_split ( ) to split the data into 25: 75 ratio.

We have obtained an accuracy score of 97.24 % and a ROC AUC score of 0.9523. We can say that our model is pretty much accurate to use.

We have used the classification report from sklearn metrics. We have generated the confusion matrix for the decision tree classifier. We have plotted it using the heat map function of the seaborn library. We have 163 false negatives and 13 true positives.
Thank you for reading our “Pokemon Analysis Project in ML and Data Science using Python” article.
Also Read:
- Download 1000+ Projects, All B.Tech & Programming Notes, Job, Resume & Interview Guide, and More – Get Your Ultimate Programming Bundle!
- Flower classification using CNN
- Music Recommendation System in Machine Learning
- 100+ Java Projects for Beginners 2023
- Courier Tracking System in HTML CSS and JS
- Test Typing Speed using Python App
- Top 15 Machine Learning Projects in Python with source code
- Top 15 Java Projects For Resume
- Top 10 Java Projects with source code
- Best 100+ Python Projects with source code
- Gender Recognition by Voice using Python
- Top 15 Python Libraries For Data Science in 2022
- Top 15 Python Libraries For Machine Learning in 2022
- Drawing Application in Python Tkinter
- Top 10 Final Year Projects for Computer Science Students
- Setup and Run Machine Learning in Visual Studio Code
- Diabetes prediction using Machine Learning
- Library Management System Project in Java
- Bank Management System Project in Java
- CS Class 12th Python Projects
- 15 Deep Learning Projects for Final year
- Machine Learning Scenario-Based Questions
- Customer Behaviour Analysis – Machine Learning and Python
- NxNxN Matrix in Python 3
- 3 V’s of Big data
- Naive Bayes in Machine Learning
- Top 10 Python Projects for Final year Students
- Automate Data Mining With Python
- Support Vector Machine(SVM) in Machine Learning
- Python OOP Projects | Source code and example
- Convert ipynb to Python
- Data Science Projects for Final Year
- Multiclass Classification in Machine Learning
- Movie Recommendation System: with Streamlit and Python-ML
- Getting Started with Seaborn: Install, Import, and Usage
- List of Machine Learning Algorithms
- Recommendation engine in Machine Learning
- Machine Learning Projects for Final Year
- ML Systems
- Python Derivative Calculator
- Mathematics for Machine Learning
- Inventory Management System Project in python
- Courier Management System project in Python
- Data Science Homework Help – Get The Assistance You Need
- How to Ace Your Machine Learning Assignment – A Guide for Beginners
- Contact Management System Project in Python
- Top 10 Resources to Find Machine Learning Datasets in 2022
- Reinforcement learning in Python
- Python SQLite Tutorial
- Student Management System Project in Python
- Face recognition Python
- 20 Python Projects for Resume
- Restaurant management system project in Python
- Employee Management System Project in Python
- Bank Management System Project in Python
- Hate speech detection with Python
- Hospital Management System Project in Python
- Attendance Management System Project in Python
- MNIST Handwritten Digit Classification using Deep Learning
- Stock Price Prediction using Machine Learning
- Control Mouse with hand gestures detection python
- Create a Vehicle Parking Management Project in Python
- Build Your Own Map Flight Tracking Application with Python
- Traffic Signal Violation Detection System using Computer Vision
- Deepfake Detection Project Using Deep-Learning
- Employment Trends Of Private & Government Sector in UAE | Data Analysis
- Pokemon Analysis Project in ML and Data Science using Python
- Garment Factory Analysis Project using Python
- Creating a Pong Game using Python Turtle
- Deploy Machine Learning model using Streamlit
- Breast Cancer Detection – Machine Learning
- 8 Steps to Build a Machine Learning Model
- Detect Eyes and Detect Faces in Python
- User Authentication System in Django Python
- Django Framework | Developing a Blog website in Django (Tutorial) Part 2
- Customer Segmentation using Python in Machine Learning
- Titanic Survival Prediction – Machine Learning Project (Part-2)
- Titanic Survival Prediction – Machine Learning Project (Part-1)
- Random Forest in ML: Wisdom of the Crowd
- K Nearest Neighbours|KNN: One of the Earliest ML Algorithm
- 3D animation in Python: vpython
- Complete Racing Game In Python Using PyGame
- Decision Tree: Foundation of Powerful ML Algorithms
- Logistic Regression: Regression Model for Classification
- Gradient Descent: Another Approach to Linear Regression
- Linear Regression: Your 1st Step in Machine Learning
- Set up Python Environment
- Seaborn: Create Elegant Plots
- Matplotlib Python: A Beginner’s Walkthrough
- Python Pandas Tutorial: A Complete Introduction for Beginners
- Numpy For Machine Learning: A Complete Guide
- Jupyter Notebook: The Ultimate Guide
- ML Environment Setup and Overview
- Machine Learning Course Description
- Machine Learning: A Gentle Introduction
- Python Assignment Help Online| Python Homework Help


